
[ad_1]

As we speak’s robots are sometimes static and remoted from people in structured environments — you possibly can consider robotic arms employed by Amazon for choosing and packaging merchandise inside warehouses. However the true potential of robotics lies in cell robots working alongside people in messy environments like our houses and hospitals — this requires navigation expertise.
Think about dropping a robotic in a very unseen dwelling and asking it to search out an object, let’s say a rest room. People can do that effortlessly: when on the lookout for a glass of water at a good friend’s home we’re visiting for the primary time, we will simply discover the kitchen with out going to bedrooms or storage closets. However educating this sort of spatial widespread sense to robots is difficult.
Many learning-based visible navigation insurance policies have been proposed to deal with this drawback. However realized visible navigation insurance policies have predominantly been evaluated in simulation. How properly do totally different lessons of strategies work on a robotic?
We current a large-scale empirical research of semantic visible navigation strategies evaluating consultant strategies from classical, modular, and end-to-end studying approaches throughout six houses with no prior expertise, maps, or instrumentation. We discover that modular studying works properly in the true world, attaining a 90% success price. In distinction, end-to-end studying doesn’t, dropping from 77% simulation to 23% real-world success price on account of a big picture area hole between simulation and actuality.
Object objective navigation
We instantiate semantic navigation with the Object Objective navigation job, the place a robotic begins in a very unseen atmosphere and is requested to search out an occasion of an object class, let’s say a rest room. The robotic has entry to solely a first-person RGB and depth digital camera and a pose sensor.
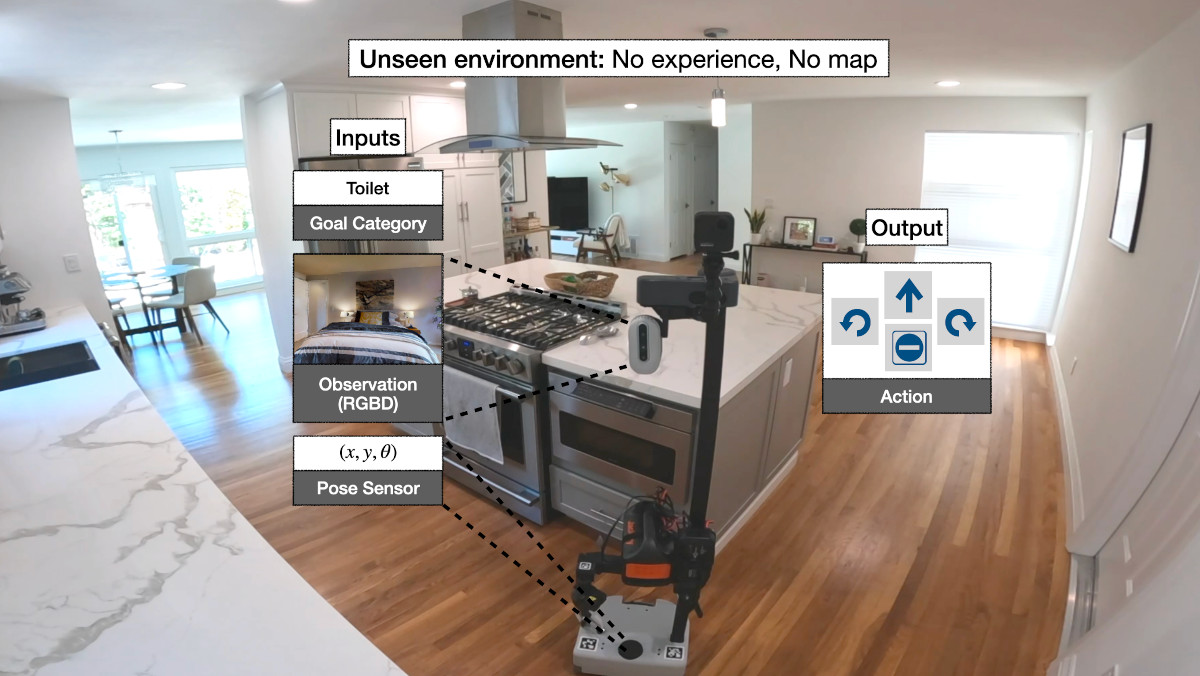
This job is difficult. It requires not solely spatial scene understanding of distinguishing free area and obstacles and semantic scene understanding of detecting objects, but additionally requires studying semantic exploration priors. For instance, if a human needs to discover a bathroom on this scene, most of us would select the hallway as a result of it’s most probably to result in a rest room. Educating this sort of widespread sense or semantic priors to an autonomous agent is difficult. Whereas exploring the scene for the specified object, the robotic additionally wants to recollect explored and unexplored areas.

Strategies
So how will we practice autonomous brokers able to environment friendly navigation whereas tackling all these challenges? A classical strategy to this drawback builds a geometrical map utilizing depth sensors, explores the atmosphere with a heuristic, like frontier exploration, which explores the closest unexplored area, and makes use of an analytical planner to achieve exploration targets and the objective object as quickly as it’s in sight. An end-to-end studying strategy predicts actions instantly from uncooked observations with a deep neural community consisting of visible encoders for picture frames adopted by a recurrent layer for reminiscence. A modular studying strategy builds a semantic map by projecting predicted semantic segmentation utilizing depth, predicts an exploration objective with a goal-oriented semantic coverage as a perform of the semantic map and the objective object, and reaches it with a planner.
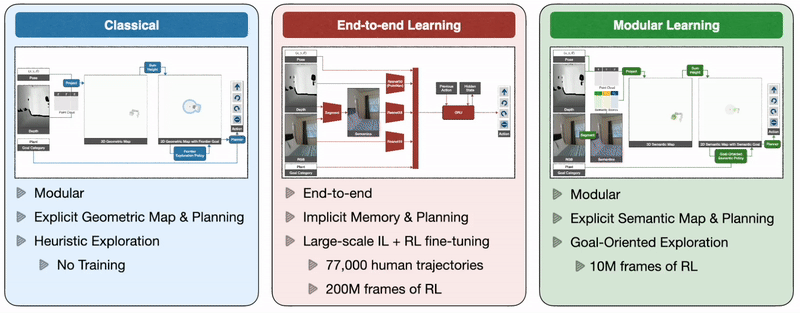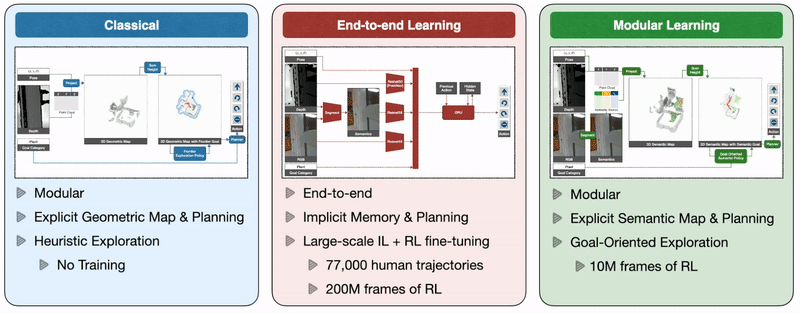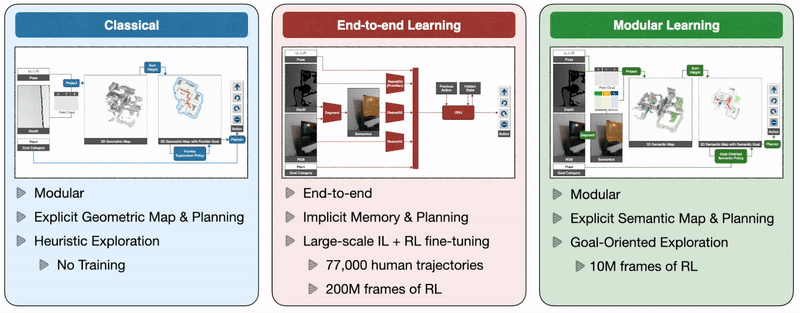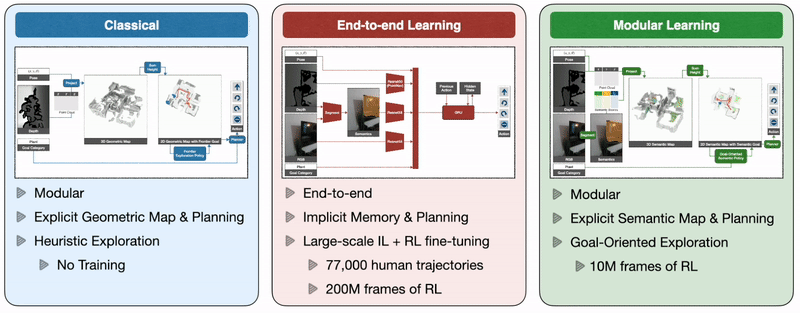
Giant-scale real-world empirical analysis
Whereas many approaches to navigate to things have been proposed over the previous few years, realized navigation insurance policies have predominantly been evaluated in simulation, which opens the sphere to the chance of sim-only analysis that doesn’t generalize to the true world. We handle this situation via a large-scale empirical analysis of consultant classical, end-to-end studying, and modular studying approaches throughout 6 unseen houses and 6 objective object classes.

Outcomes
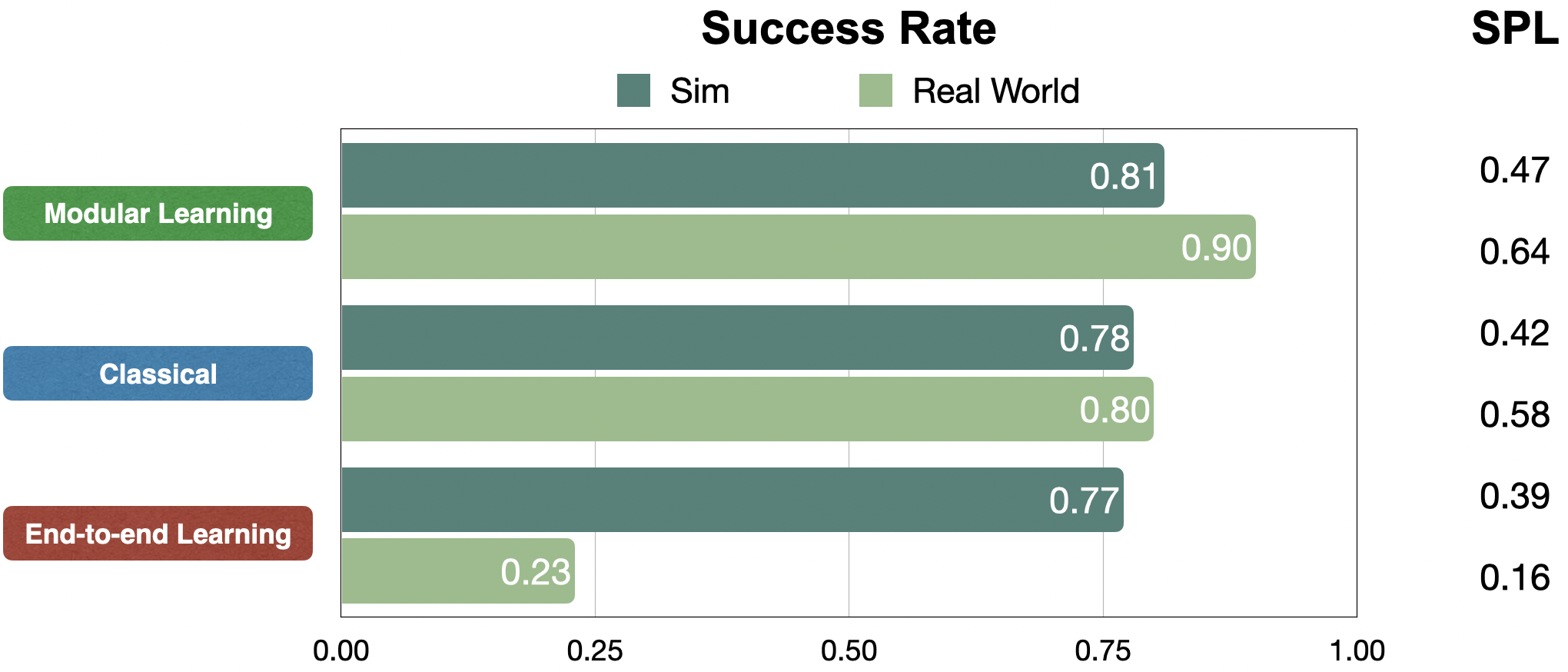
We evaluate approaches by way of success price inside a restricted funds of 200 robotic actions and Success weighted by Path Size (SPL), a measure of path effectivity. In simulation, all approaches carry out comparably, at round 80% success price. However in the true world, modular studying and classical approaches switch very well, up from 81% to 90% and 78% to 80% success charges, respectively. Whereas end-to-end studying fails to switch, down from 77% to 23% success price.
We illustrate these outcomes qualitatively with one consultant trajectory. All approaches begin in a bed room and are tasked with discovering a sofa. On the left, modular studying first efficiently reaches the sofa objective. Within the center, end-to-end studying fails after colliding too many occasions. On the best, the classical coverage lastly reaches the sofa objective after a detour via the kitchen.
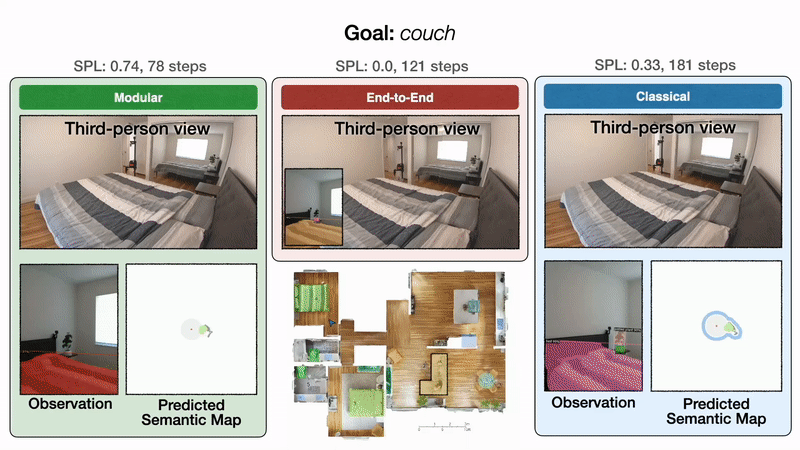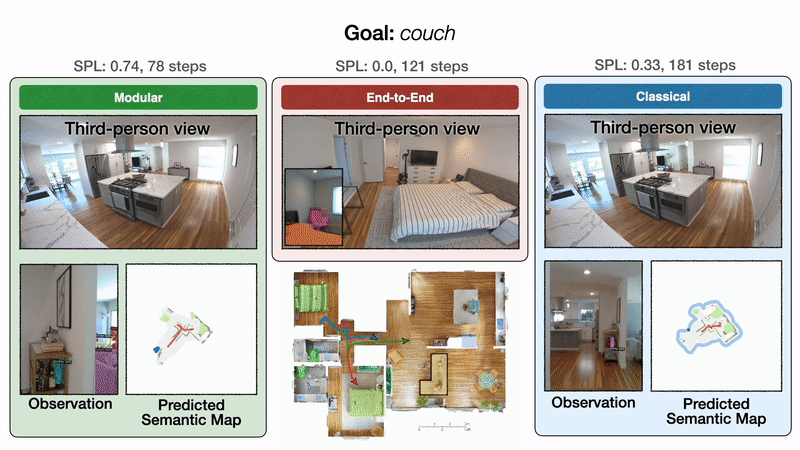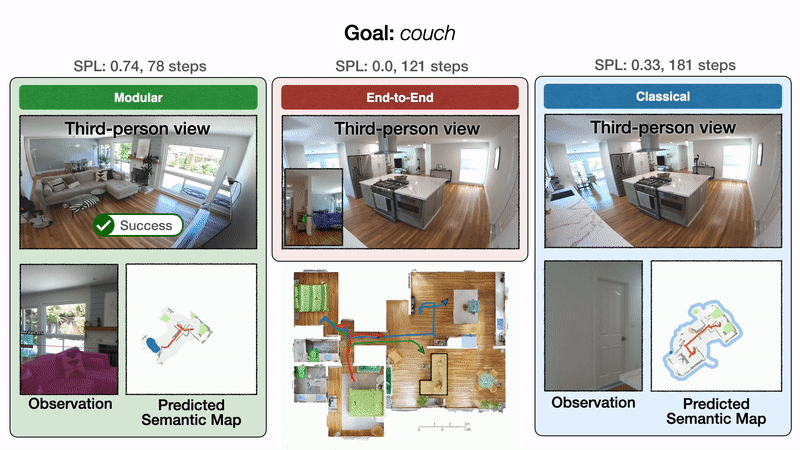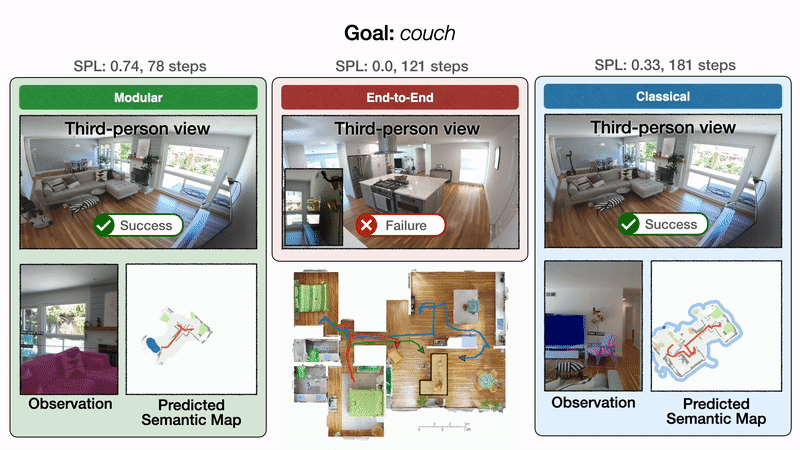
End result 1: modular studying is dependable
We discover that modular studying could be very dependable on a robotic, with a 90% success price. Right here, we will see it finds a plant in a primary dwelling effectively, a chair in a second dwelling, and a rest room in a 3rd.

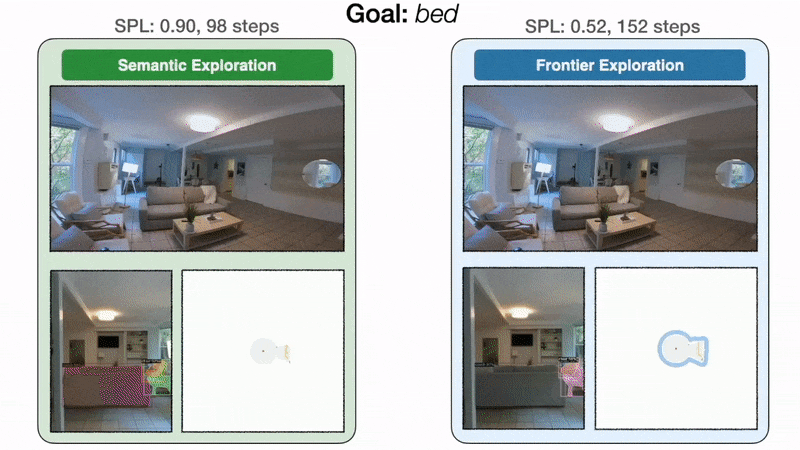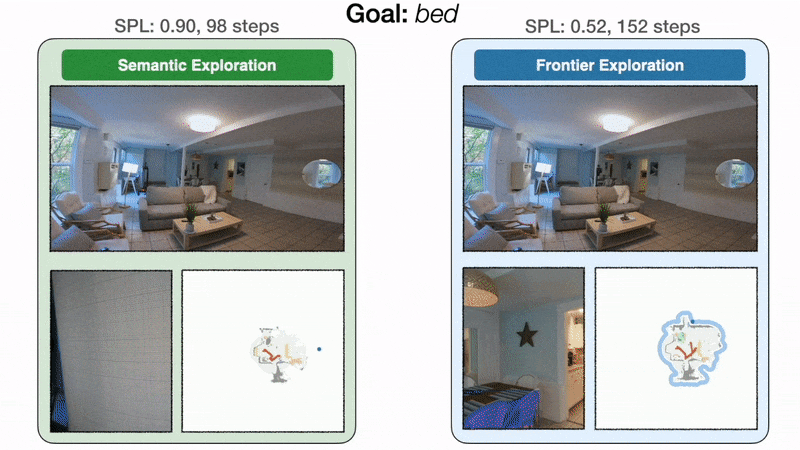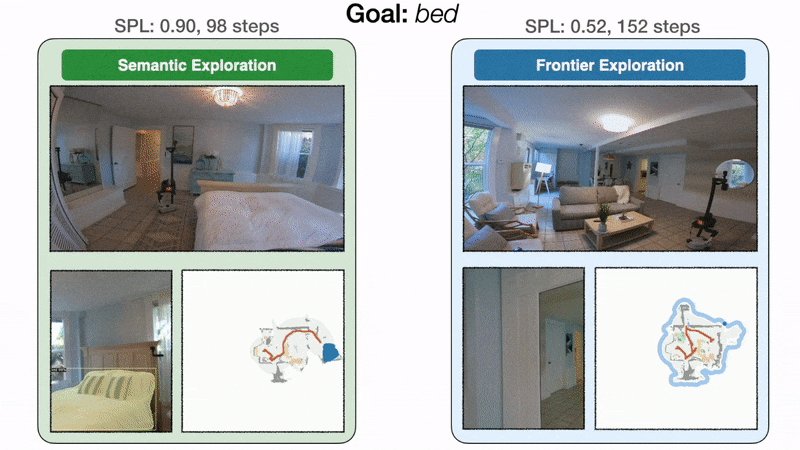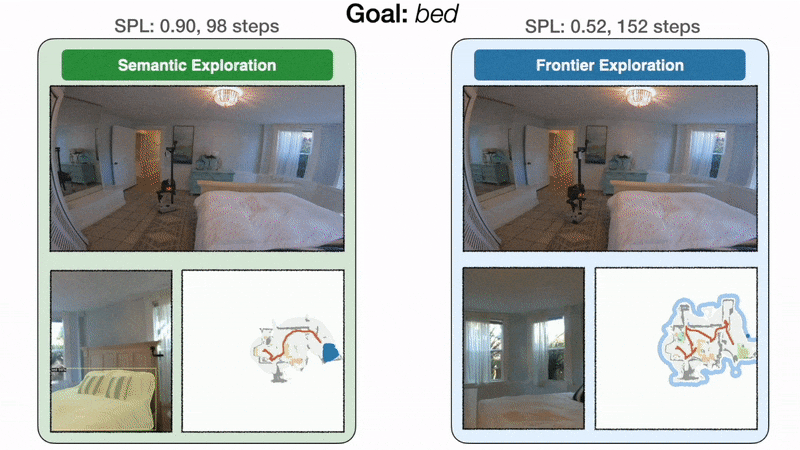
End result 2: modular studying explores extra effectively than classical
Modular studying improves by 10% real-world success price over the classical strategy. On the left, the goal-oriented semantic exploration coverage instantly heads in direction of the bed room and finds the mattress in 98 steps with an SPL of 0.90. On the best, as a result of frontier exploration is agnostic to the mattress objective, the coverage makes detours via the kitchen and the doorway hallway earlier than lastly reaching the mattress in 152 steps with an SPL of 0.52. With a restricted time funds, inefficient exploration can result in failure.
End result 3: end-to-end studying fails to switch
Whereas classical and modular studying approaches work properly on a robotic, end-to-end studying doesn’t, at solely 23% success price. The coverage collides usually, revisits the identical locations, and even fails to cease in entrance of objective objects when they’re in sight.

Evaluation
Perception 1: why does modular switch whereas end-to-end doesn’t?
Why does modular studying switch so properly whereas end-to-end studying doesn’t? To reply this query, we reconstructed one real-world dwelling in simulation and performed experiments with an identical episodes in sim and actuality.

The semantic exploration coverage of the modular studying strategy takes a semantic map as enter, whereas the end-to-end coverage instantly operates on the RGB-D frames. The semantic map area is invariant between sim and actuality, whereas the picture area reveals a big area hole. On this instance, this hole results in a segmentation mannequin skilled on real-world photos to foretell a mattress false optimistic within the kitchen.
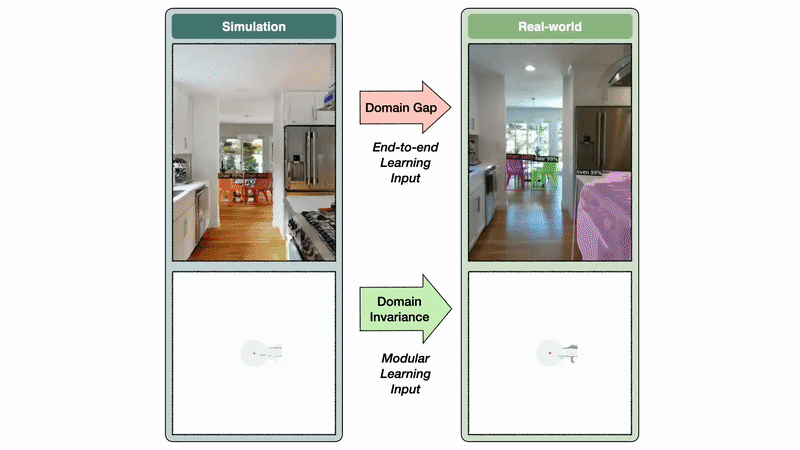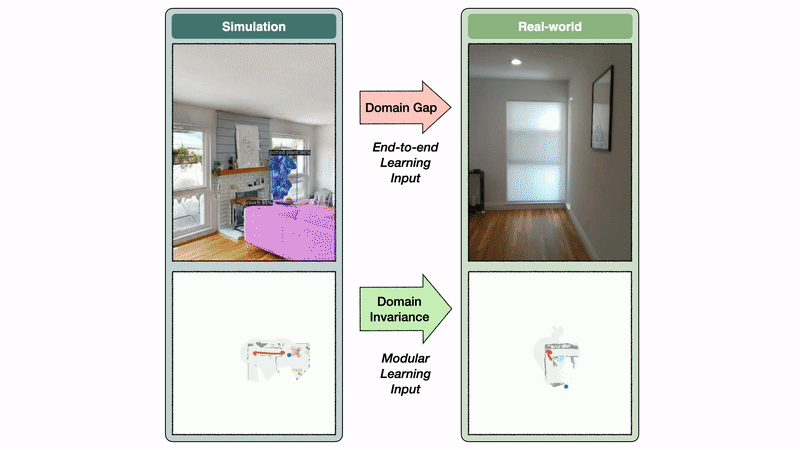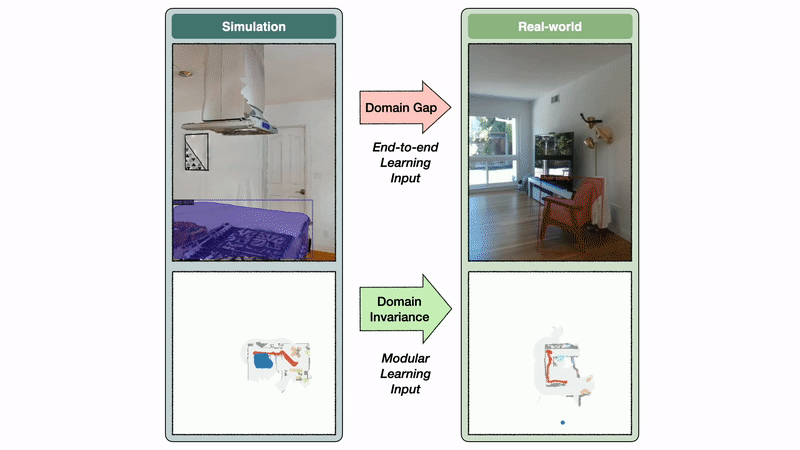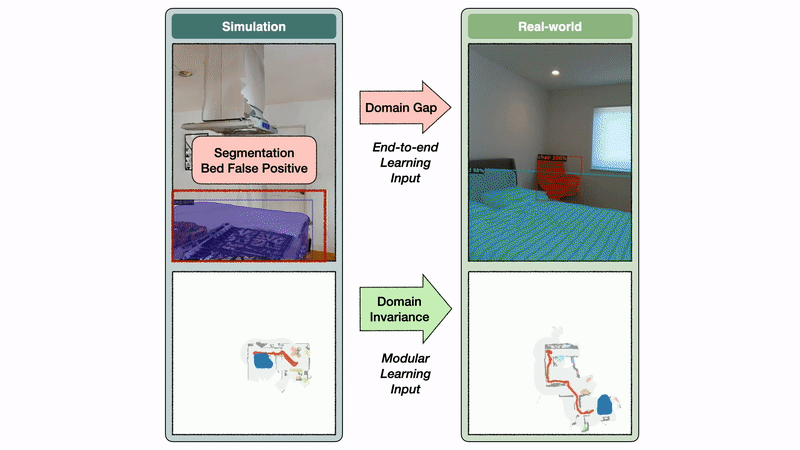
The semantic map area invariance permits the modular studying strategy to switch properly from sim to actuality. In distinction, the picture area hole causes a big drop in efficiency when transferring a segmentation mannequin skilled in the true world to simulation and vice versa. If semantic segmentation transfers poorly from sim to actuality, it’s affordable to anticipate an end-to-end semantic navigation coverage skilled on sim photos to switch poorly to real-world photos.
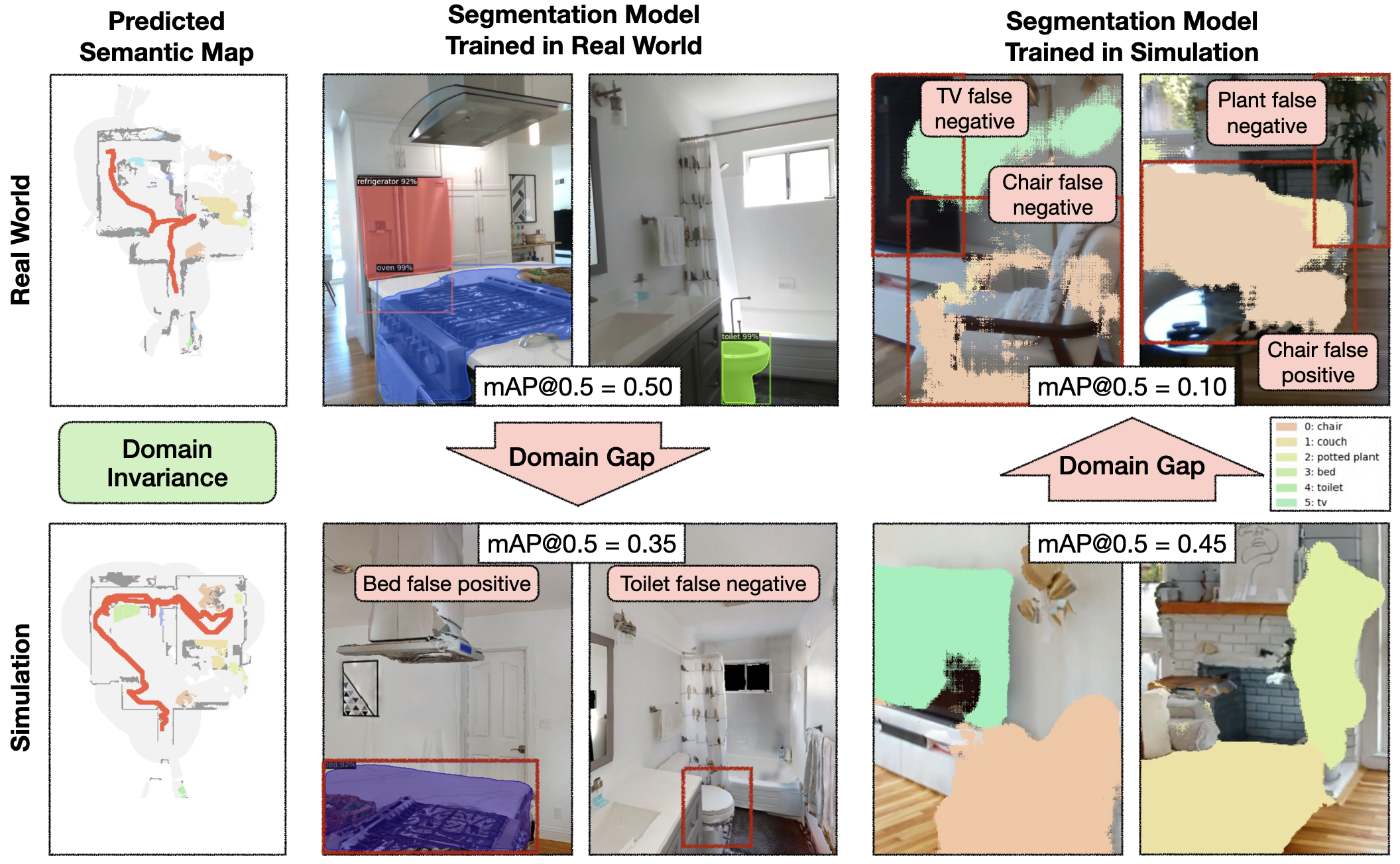
Perception 2: sim vs actual hole in error modes for modular studying
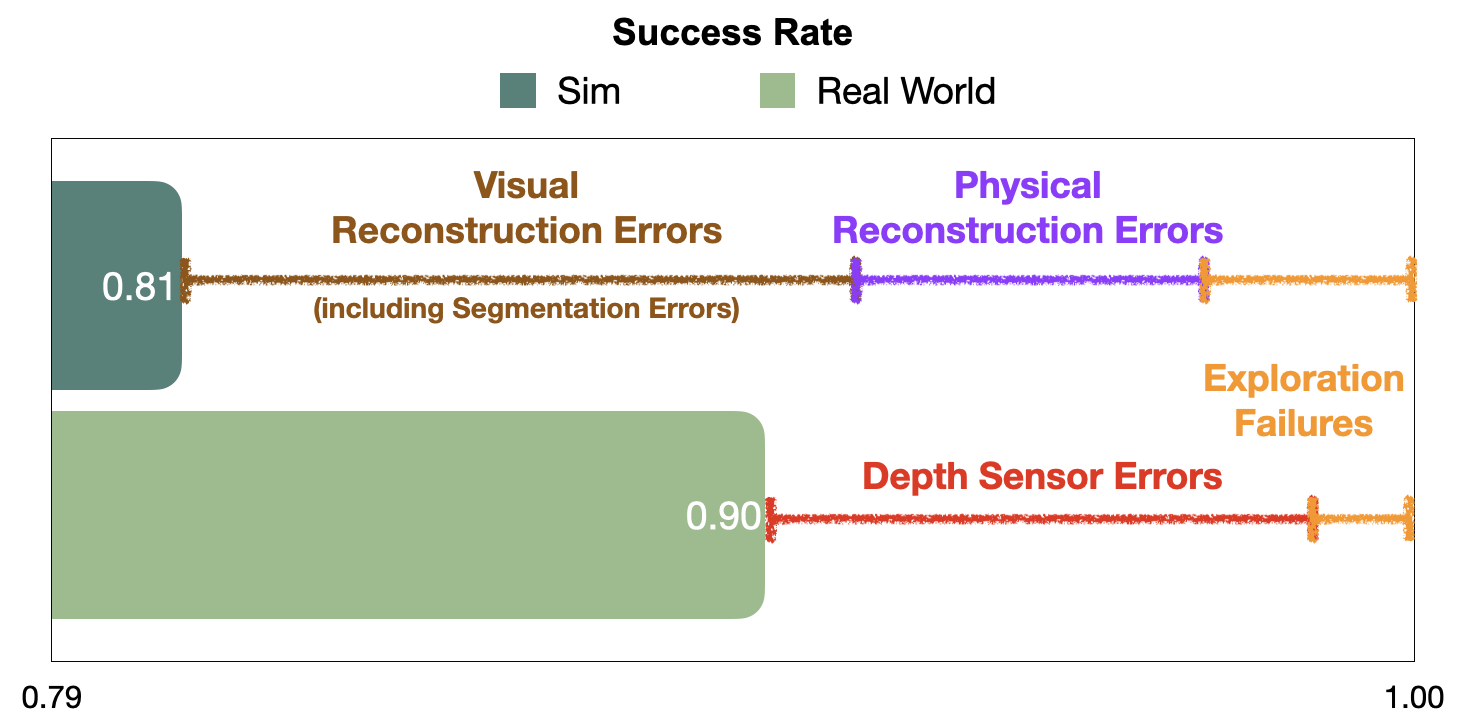
Surprisingly, modular studying works even higher in actuality than simulation. Detailed evaluation reveals that lots of the failures of the modular studying coverage that happen in sim are on account of reconstruction errors, which don’t occur in actuality. Visible reconstruction errors signify 10% out of the overall 19% episode failures, and bodily reconstruction errors one other 5%. In distinction, failures in the true world are predominantly on account of depth sensor errors, whereas most semantic navigation benchmarks in simulation assume excellent depth sensing. Apart from explaining the efficiency hole between sim and actuality for modular studying, this hole in error modes is regarding as a result of it limits the usefulness of simulation to diagnose bottlenecks and additional enhance insurance policies. We present consultant examples of every error mode and suggest concrete steps ahead to shut this hole within the paper.
Takeaways
For practitioners:
- Modular studying can reliably navigate to things with 90% success.
For researchers:
- Fashions counting on RGB photos are laborious to switch from sim to actual => leverage modularity and abstraction in insurance policies.
- Disconnect between sim and actual error modes => consider semantic navigation on actual robots.
For extra content material about robotics and machine studying, try my weblog.

Theophile Gervet
is a PhD scholar on the Machine Studying Division at Carnegie Mellon College
Theophile Gervet
is a PhD scholar on the Machine Studying Division at Carnegie Mellon College
[ad_2]