
[ad_1]
Autonomous Robotics within the Period of Massive Multimodal Fashions

In my current work on Multiformer, I explored the facility of light-weight hierarchical imaginative and prescient transformers to effectively carry out simultaneous studying and inference on a number of laptop imaginative and prescient duties important for robotic notion. This “shared trunk” idea of a standard spine feeding options to a number of job heads has turn out to be a well-liked strategy in multi-task studying, notably in autonomous robotics, as a result of it has repeatedly been demonstrated that studying a function area that’s helpful for a number of duties not solely produces a single mannequin which may carry out a number of duties given a single enter, but in addition performs higher at every particular person job by leveraging the complementary data discovered from different duties.
Historically, autonomous car (AV) notion stacks kind an understanding of their environment by performing simultaneous inference on a number of laptop imaginative and prescient duties. Thus, multi-task studying with a standard spine is a pure selection, offering a best-of-both-worlds answer for parameter effectivity and particular person job efficiency. Nonetheless, the rise of huge multimodal fashions (LMMs) challenges this environment friendly multi-task paradigm. World fashions created utilizing LMMs possess the profound skill to know sensor information at each a descriptive and anticipatory degree, shifting past task-specific processing to holistic understanding of the setting and its future states (albeit with a far larger parameter depend).
On this new paradigm, which has been dubbed AV2.0, duties like semantic segmentation and depth estimation turn out to be emergent capabilities of fashions possessing a a lot deeper understanding of the info, and for which performing such duties turns into superfluous for any cause aside from relaying this information to people. Actually, your complete level of performing these middleman duties in a notion stack was to ship these predictions into additional layers of notion, planning, and management algorithms, which might then lastly describe the connection of the ego with its environment and the proper actions to take. Against this, if a bigger mannequin is ready to describe the complete nature of a driving state of affairs, all the best way as much as and together with the proper driving motion to take given the identical inputs, there’s no want for lossy middleman representations of data, and the community can be taught to reply on to the info. On this framework, the divide between notion, planning, and management is eradicated, making a unified structure that may be optimized end-to-end.
Whereas it’s nonetheless a burgeoning faculty of thought, end-to-end autonomous driving options utilizing generative world fashions constructed with LMMs is a believable long run winner. It continues a pattern of simplifying beforehand advanced options to difficult issues via sequence modeling formulations, which began in pure language processing (NLP), rapidly prolonged into laptop imaginative and prescient, and now appears to have taken a agency maintain in Reinforcement Studying (RL). Additional, these previously distinct areas of analysis have gotten unified underneath a this frequent framework, and mutually accelerating consequently. For AV analysis, accepting this paradigm shift additionally means catching the wave of speedy acceleration in infrastructure and methodology for the coaching, fine-tuning, and deployment of huge transformer fashions, as researchers from a number of disciplines proceed to climb aboard and add momentum to the obvious “intelligence is a sequence modeling drawback” phenomenon.
However what does this imply for conventional modular AV stacks? Are multi-task laptop imaginative and prescient fashions like Multiformer sure for obsolescence? It appears clear that for easy issues, akin to an software requiring primary picture classification over a recognized set of courses, a big mannequin is overkill. Nonetheless, for advanced functions like autonomous robotics, the reply is way much less apparent at this stage. Massive fashions include severe drawbacks, notably of their reminiscence necessities and resource-intensive nature. Not solely do they inflict massive monetary (and environmental) prices to coach, however deployment potentialities are restricted as nicely: the bigger the mannequin, the bigger the embedded system (robotic) should be. Growth of huge fashions thus has an actual barrier to entry, which is sure to discourage adoption by smaller outfits. However, the attract of huge mannequin capabilities has generated world momentum within the improvement of accessible strategies for his or her coaching and deployment, and this pattern is sure to proceed.
In 2019, Wealthy Sutton remarked on “The Bitter Lesson” in AI analysis, establishing that again and again, throughout disciplines from pure language to laptop imaginative and prescient, advanced approaches incorporating handcrafted parts primarily based on human data in the end turn out to be time-wasting lifeless ends which might be outdated considerably by extra common strategies that leverage uncooked computation. At present, the appearance of huge transformers and the skillful shoehorning of varied issues into self-supervised sequence modeling duties are the most important gasoline burning out the lifeless wooden of disjoint and bespoke drawback formulations. Now, longstanding approaches in RL and Time Sequence Evaluation, together with vetted heroes just like the Recurrent Neural Community (RNN), should defend their usefulness, or be a part of SIFT and rule-based language fashions in retirement. With regards to AV stack improvement, ought to we choose to interrupt the cycle of ensnaring traditions and make the change to massive world modeling prior to later, or can the accessibility and interpretability of conventional modular driving stacks stand up to the surge of huge fashions?
This text tells the story of an intriguing confluence of analysis traits that may information us towards an informed reply to this query. First, we evaluation conventional modular AV stack improvement, and the way multi-task studying results in enhancements by leveraging generalized data in a shared parameter area. Subsequent, we journey via the meteoric rise of huge language fashions (LLMs) and their enlargement into multimodality with LMMs, setting the stage for his or her influence in robotics. Then, we be taught concerning the historical past of world modeling in RL, and the way the appearance of LMMs stands to ignite a robust revolution by bestowing these world fashions with the extent of reasoning and semantic understanding seen in at present’s massive fashions. We then examine the strengths and weaknesses of this huge world modeling strategy towards conventional AV stack improvement, exhibiting that giant fashions supply nice benefits in simplified structure, end-to-end optimization in a high-dimensional area, and extraordinary predictive energy, however they achieve this at the price of far larger parameter counts that pose a number of engineering challenges. With this in thoughts, we evaluation a number of promising strategies for overcoming these engineering challenges with the intention to make the event and deployment of those massive fashions possible. Lastly, we replicate on our findings to conclude that whereas massive world fashions are favorably located to turn out to be the long-term winner, the teachings discovered from conventional strategies will nonetheless be related in maximizing their success. We shut with a dialogue highlighting some promising instructions for future work on this thrilling area.
Multi-task Studying in Pc Imaginative and prescient and AVs
Multi-task studying (MTL) is an space that has seen substantial analysis focus, usually described as a serious step in direction of human-like reasoning in synthetic intelligence (AI). As outlined in Michael Crawshaw’s complete survey on the topic, MTL entails coaching a mannequin on a number of duties concurrently, permitting it to leverage shared info throughout these duties. This strategy is just not solely helpful when it comes to computational effectivity but in addition results in improved job efficiency as a result of complementary nature of the discovered options. Crawshaw’s survey emphasizes that MTL fashions usually outperform their single-task counterparts by studying extra strong and generalized representations.
We consider that MTL displays the training technique of human beings extra precisely than single job studying in that integrating data throughout domains is a central tenant of human intelligence. When a new child child learns to stroll or use its arms, it accumulates common motor expertise which depend on summary notions of steadiness and intuitive physics. As soon as these motor expertise and summary ideas are discovered, they are often reused and augmented for extra advanced duties later in life, akin to driving a motorbike or tightrope strolling.
The advantages of MTL are notably related within the context of AVs, which require real-time inference of a number of associated imaginative and prescient duties to make protected navigation choices. MultiNet is a main instance of a MTL mannequin designed for AVs, combining duties like street segmentation, object detection, and classification inside a unified structure. The mixing of MTL in AVs brings notable benefits like larger framerate and decreased reminiscence footprint, essential for the various scales of autonomous robotics.
https://medium.com/media/d8381826107d52f6c089ca8690f012e1/href
Transformer-based networks akin to Imaginative and prescient Transformer (ViT) and its derivatives have proven unimaginable descriptive capability in laptop imaginative and prescient, and the fusion of transformers with convolutional architectures within the type of hierarchical transformers just like the Pyramid Imaginative and prescient Transformer v2 (PVTv2) have confirmed notably potent and simple to coach, persistently outperforming ResNet backbones with fewer parameters in current fashions like Segformer, GLPN, and Panoptic Segformer. Motivated by the will for a robust but light-weight notion module, Multiformer combines the complementary strengths supplied by MTL and the descriptive energy of hierarchical transformers to attain adept simultaneous efficiency on semantic segmentation, depth estimation, and 2D object detection with simply over 8M (million) parameters, and is quickly extensible to panoptic segmentation.
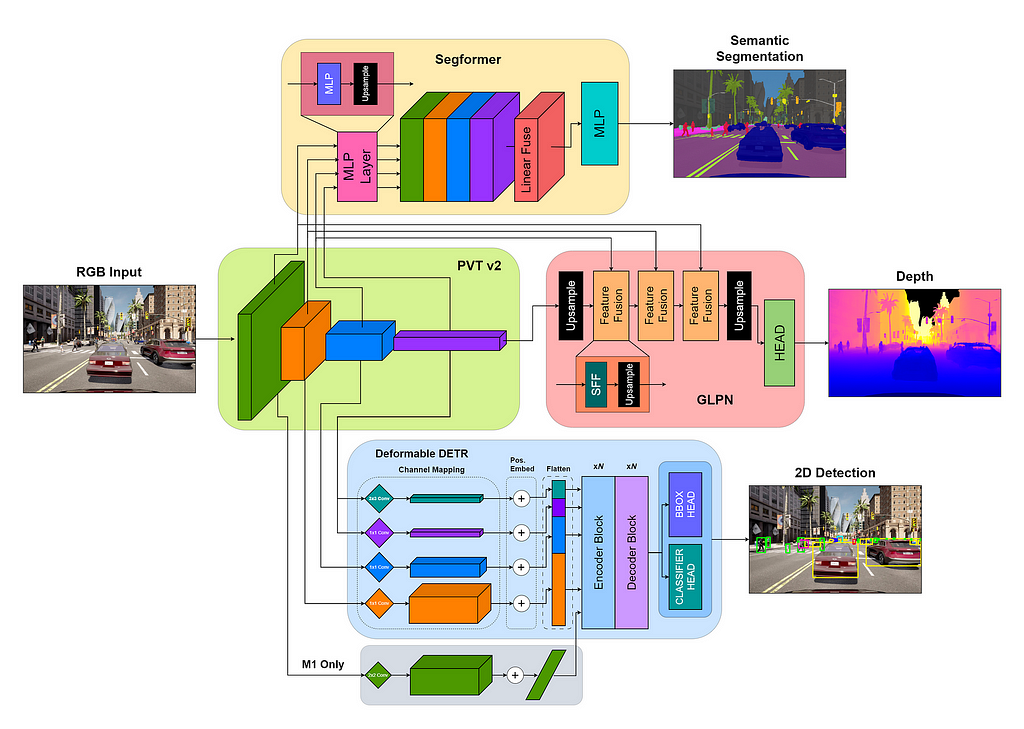
Constructing a full autonomy stack, nonetheless, requires greater than only a notion module. We additionally must plan and execute actions, so we have to add a planning and management module which may use the outputs of the notion stack to precisely observe and predict the states of the ego and its setting with the intention to ship instructions that symbolize protected driving actions. One promising choice for that is Nvidia’s DiffStack, which provides a trainable but interpretable mixture of trajectory forecasting, path planning, and management modeling. Nonetheless, this module requires 3D agent poses as an enter, which suggests our notion stack should generate them. Happily, there are algorithms obtainable for 3D object detection, notably when correct depth info is out there, however our object monitoring goes to be extraordinarily delicate to our accuracy and temporal consistency on this tough job, and any errors will propagate and diminish the standard of the downstream movement planning and management.
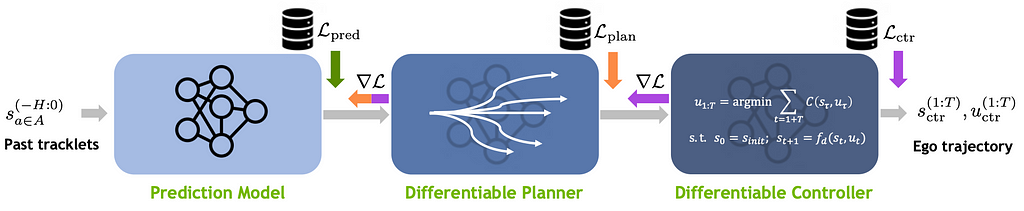
Certainly, the normal modular paradigm of autonomy stacks, with its distinct phases from sensor enter via notion, planning, and management, is inherently prone to compounding errors. Every stage within the sequence is reliant on the accuracy of the previous one, which makes the system susceptible to a cascade of errors, and impedes end-to-end error correction via crystallization of middleman info. Then again, the modular strategy is extra interpretable than an end-to-end system because the middleman representations will be understood and identified. It is because of this that end-to-end techniques have usually been averted, seen as “black field” options with an unacceptable lack of interpretability for a safety-critical software of AI like autonomous navigation. However what if the interpretability situation may very well be overcome? What if these black bins might clarify the selections they made in plain English, or some other pure language? Enter the period of LMMs in autonomous robotics, the place this imaginative and prescient is just not some distant dream, however a tangible actuality.
Autoregressive Transformers and The Rise of LLMs

In what turned out to be probably the most impactful analysis papers of our time, Vaswani et al. launched the transformer structure in 2017 with “Consideration is All You Want,” revolutionizing sequence-to-sequence (seq2seq) modeling with their proposed consideration mechanisms. These modern modules overcame the weaknesses of the beforehand favored RNNs by successfully capturing long-range dependencies in sequences and permitting extra parallelization throughout computation, resulting in substantial enhancements in numerous seq2seq duties. A yr later, Google’s Bidirectional Encoder Representations from Transformers (BERT) strengthened transformer capabilities in NLP by introducing a bidirectional pretraining goal utilizing masked language modeling (MLM) to fuse each the left and proper contexts, encoding a extra nuanced contextual understanding of every token, and empowering quite a lot of language duties like sentiment evaluation, query answering, machine translation, textual content summarization, and extra.
In mid-2018, researchers at OpenAI demonstrated coaching a causal decoder-only transformer to work on byte pair encoded (BPE) textual content tokens with the Generative Pretrained Transformer (GPT). They discovered that pretraining on a self-supervised autoregressive language modeling job utilizing massive corpuses of unlabeled textual content information, adopted by task-specific fine-tuning with task-aware enter transformations (and architectural modifications when essential), produced fashions which considerably improved state-of-the-art on quite a lot of language duties.
Whereas the task-aware enter transformations within the token area utilized by GPT-1 will be thought of an early type of “immediate engineering,” the time period most generally refers back to the strategic structuring of textual content to elicit multi-task conduct from language fashions demonstrated by researchers from Salesforce in 2018 with their influential Multitask Query Answering Community (MQAN). By framing duties as strings of textual content with distinctive formatting, the authors educated a single mannequin with no task-specific modules or parameters to carry out nicely at a set of ten NLP duties which they known as the “Pure Language Decathlon” (decaNLP).
In 2019, OpenAI discovered that by adopting this type of immediate engineering at inference time, GPT-2 elicited promising zero-shot multi-task efficiency that scaled log-linearly with the dimensions of the mannequin and dataset. Whereas these job immediate buildings weren’t explicitly included within the coaching information the best way they had been for MQAN, the mannequin was in a position to generalize data from structured language that it had seen earlier than to finish the duty at hand. The mannequin demonstrated spectacular unsupervised multi-task studying with 1.5B parameters (up from 117M in GPT), indicating that this type of language modeling posed a promising path towards generalizable AI, and elevating moral considerations for the future.
Google analysis open-sourced the text-to-text switch transformer (T5) in late 2019, with mannequin sizes ranging as much as 11B parameters. Whereas additionally constructed with an autoregressive transformer, T5 represents pure language issues in a unified text-to-text framework utilizing the complete transformer structure (full with the encoder), differing from the following token prediction job of GPT-style fashions. Whereas this text-to-text framework is a powerful selection for functions requiring extra management over job coaching and anticipated outputs, the following token prediction scheme of GPT-style fashions turned favored for its task-agnostic coaching and freeform era of lengthy coherent responses to consumer inputs.
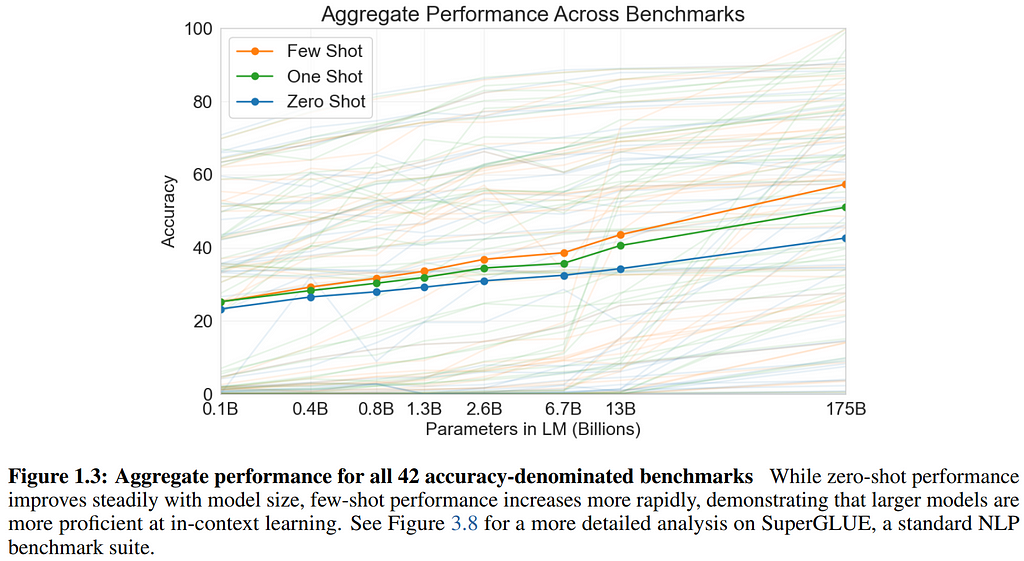
Then in 2020, OpenAI took mannequin and information scaling to unprecedented heights with GPT-3, and the remainder is historical past. Of their paper titled “Language Fashions are Few-Shot Learners,” the authors outline a “few-shot” switch paradigm the place they supply no matter variety of examples for an unseen job (formulated as pure language) will match into the mannequin’s context earlier than the ultimate open-ended immediate of this job for the mannequin to finish. They distinction this with “one-shot,” the place one instance is offered in context, and “zero-shot,” the place no examples are offered in any respect. The staff discovered that efficiency on all three analysis strategies continued to scale all the best way to 175B parameters, a historic step change in printed mannequin sizes. This behemoth achieved generalist few-shot studying and textual content era talents approaching the extent of people, prompting mainstream consideration, and spurring considerations for the longer term implications of this pattern in AI analysis. These involved might discover non permanent solace in the truth that at these scales, coaching and fine-tuning of those fashions had been delivered removed from the purview of all however the largest outfits, however this could absolutely change.
Groundbreaking on many fronts, GPT-3 additionally marked the tip of OpenAI’s openness, the primary of its closed-source fashions. Happily for the analysis neighborhood, the wave of open-source LLM analysis had already begun. EleutherAI launched a well-liked sequence of huge open-source GPT-3-style fashions beginning with GPT-Neo 2.7B in 2020, persevering with on to GPT-J 6B in 2021, and GPT-NeoX 20B in 2022, with the latter giving GPT-3.5 DaVinci a run for its cash within the benchmarks (all can be found in huggingface/transformers).
The next years marked a Cambrian Explosion of transformer-based LLMs. A supernova of analysis curiosity has produced a panoramic checklist of publications for which a full evaluation is nicely outdoors the scope of this text, however I refer the reader to Zhao et al. 2023 for a complete survey. Just a few key developments deserving point out are, in fact, OpenAI’s launch of GPT-4, together with Meta AI’s open-source launch of the fecund LLaMA, the potent Mistral 7B mannequin, and its mixture-of-experts (MoE) model: Mixtral 8X7B, all in 2023. It’s broadly believed that GPT-4 is a MoE system, and the facility demonstrated by Mixtral 8X7B (outperforming LLaMA 2 70B on most benchmarks with 6x quicker inference) supplies compelling proof.
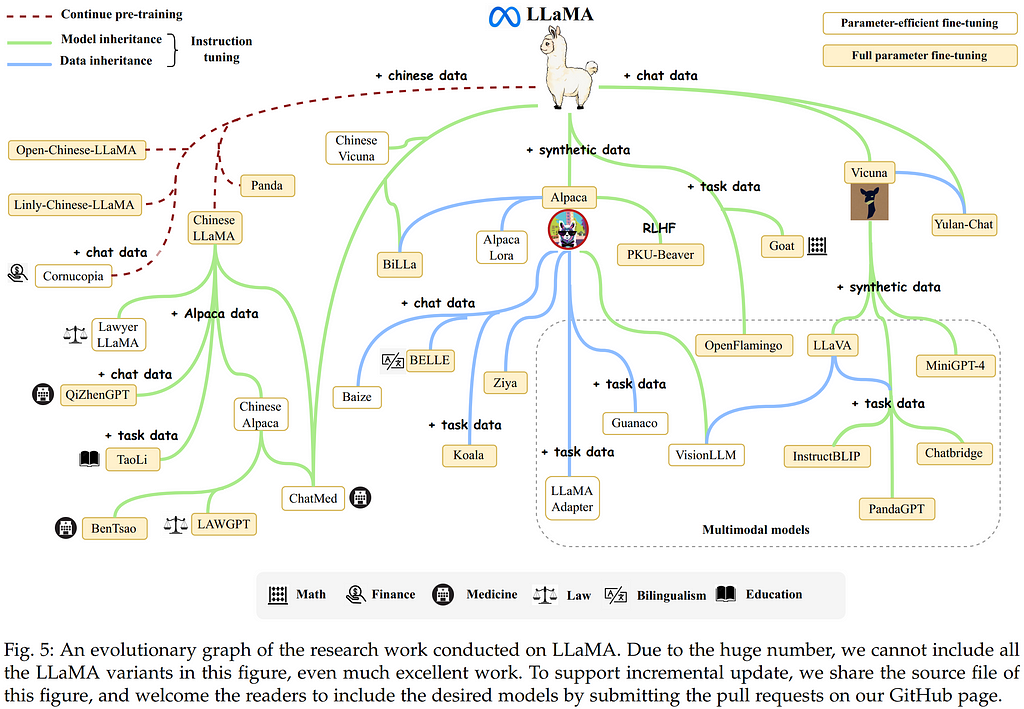
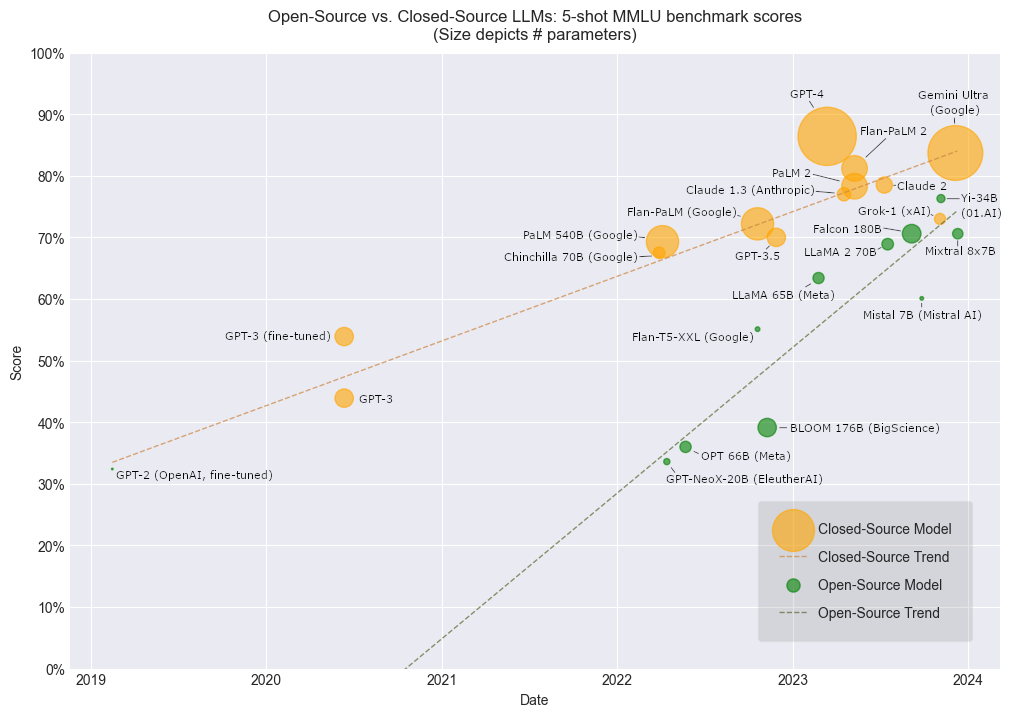
For a concise visible abstract of the LLM Massive Bang over the previous years, it’s useful to borrow as soon as extra from the highly effective Zhao et al. 2023 survey. Take into accout this chart solely consists of fashions over 10B parameters, so it misses some necessary smaller fashions like Mistral 7B. Nonetheless, it supplies a helpful visible anchor for current developments, in addition to a testomony to the quantity of analysis momentum that fashioned after T5 and GPT-3.
It’s price noting that whereas open-source LLMs have understandably lagged behind personal fashions when it comes to efficiency, that hole is narrowing over time, and open fashions appear poised to catch up within the close to future. It might seem there’s no time like the current to turn out to be familiarized with the mixing of LLMs into our work.
The Period of Massive Multimodal Fashions
Increasing on the resounding success of LLMs, the latest period in synthetic intelligence has seen the appearance of LMMs, representing a paradigm shift in how machines perceive and work together with the world. These massive fashions can take a number of modalities of information as enter, return a number of modalities of information as output, or each, by studying a shared embedding area throughout these information modalities and sequence modeling that area utilizing LLMs. This enables LMMs to carry out groundbreaking feats like visible query answering utilizing pure language, as proven on this demonstration of the Massive Language and Imaginative and prescient Assistant (LLaVA):

A big stride in visual-language pretraining (VLP), OpenAI’s Contrastive Language-Picture Pre-training (CLIP) unlocked a brand new degree of potentialities in 2021 when it established a contrastive technique for studying a shared visible and language embedding area, permitting photographs and textual content to be represented in a mutual numeric area and matched primarily based on cosine similarity scores. CLIP set off a revolution in laptop imaginative and prescient when it was in a position to beat the state-of-the-art on a number of picture classification benchmarks in a zero-shot vogue, surpassing skilled fashions that had been educated utilizing supervision, and making a surge of analysis curiosity in zero-shot classification. Whereas it stopped in need of capabilities like visible query answering, coaching CLIP produces a picture encoder that may be eliminated and paired with a LLM to create a LMM. For instance, the LLaVA mannequin (seen demonstrated above) encodes photographs into the multimodal embedding area utilizing a pretrained and frozen CLIP picture encoder, as does DeepMind’s Flamingo.
*Be aware* — terminology for LMMs is just not fully constant. Though “LMM” appears to have turn out to be the preferred, these fashions are referred to elsewhere as MLLMs, and even MM-LLMs.
Picture embeddings generated by these pretrained CLIP encoders will be interleaved with textual content embeddings in an autoregressive transformer language mannequin. AudioCLIP added audio as a 3rd modality to the CLIP framework to beat the state-of-the-art within the Environmental Sound Classification (ESC) job. Meta AI’s influential ImageBind presents a framework for studying to encode joint embeddings throughout six information modalities: picture, textual content, audio, depth, thermal, and Inertial Mass Unit (IMU) information, however demonstrates that emergent alignment throughout all modalities happens by aligning every of them with the photographs solely, demonstrating the wealthy semantic content material of photographs (an image actually is price a thousand phrases). PandaGPT mixed the multimodal encoding scheme of ImageBind with the Vicuna LLM to create a LMM which understands information enter in these six modalities, however like the opposite fashions talked about up to now, is restricted to textual content output solely.
Picture is maybe essentially the most versatile format for mannequin inputs, as it may be used to symbolize textual content, tabular information, audio, and to some extent, movies. There’s additionally a lot extra visible information than textual content information. We’ve telephones/webcams that continuously take footage and movies at present.
Textual content is a way more highly effective mode for mannequin outputs. A mannequin that may generate photographs can solely be used for picture era, whereas a mannequin that may generate textual content can be utilized for a lot of duties: summarization, translation, reasoning, query answering, and so forth.
— Eager abstract of information modality strengths from Huyen’s “Multimodality and Massive Multimodal Fashions (LMMs)” (2023).
Actually, the vast majority of analysis in LMMs has solely supplied unimodal language output, with the event of fashions returning information in a number of modalities lagging by comparability. These works which have sought to offer multimodal output have predominantly guided the era within the different modalities utilizing decoded textual content from the LLM (e.g. when prompted for a picture, GPT-4 will generate a specialised immediate in pure language and cross this to DALL-E 3, which then creates the picture for the consumer), and this inherently introduces danger for cascading error and prevents end-to-end tuning. NExT-GPT seeks to handle this situation, designing an all-to-all LMM that may be educated end-to-end. On the encoder facet, NExT-GPT makes use of the ImageBind framework talked about above. For guiding decoding throughout the 6 modalities, the LMM is fine-tuned on a custom-made modality-switching instruction tuning dataset known as Mosit, studying to generate particular modality sign tokens which function directions to the decoding course of. This enables for the dealing with of information output modality switching to be discovered end-to-end.
GATO, developed by DeepMind in 2022, is a generalist agent that epitomizes the exceptional versatility of LMMs. This singular system demonstrated an unprecedented skill to carry out a wide selection of 604 distinct duties, starting from Atari video games to advanced management duties like stacking blocks with an actual robotic arm, all inside a unified studying framework. The success of GATO is a testomony to the potential of LMMs to emulate human-like adaptability throughout various environments and duties, inching nearer to the elusive objective of synthetic common intelligence (AGI).
World Fashions within the Period of LMMs
Deep Reinforcement Studying (RL) is a well-liked and well-studied strategy to fixing advanced issues in robotics, first demonstrating superhuman functionality in Atari video games, then later beating the world’s prime gamers of Go (a famously difficult sport requiring long-term technique). Conventional deep RL algorithms are usually categorized as both a model-free or model-based strategy, though current work blurs this line via framing RL as a big sequence modeling drawback utilizing massive transformer fashions, following the profitable pattern in NLP and laptop imaginative and prescient.
Whereas demonstrably efficient and simpler to design and implement than model-based approaches, model-free RL approaches are notoriously extra pattern inefficient, requiring way more interactions with an setting to be taught a job than people do. Mannequin-based RL approaches require fewer interactions by studying to mannequin how the setting modifications given earlier states and actions. These fashions can be utilized to anticipate future states of the setting, however this provides a failure mode to RL techniques, since they need to rely on the accuracy and feasibility of this modeling. There’s a lengthy historical past of utilizing neural networks to be taught dynamics fashions for coaching RL insurance policies, relationship again to the Eighties utilizing feed-forward networks (FFNs), and to the Nineties with RNNs, with the latter changing into the dominant strategy because of their skill to mannequin and predict over multi-step time horizons.
In 2018, Ha & Schmidhuber launched a pivotal piece of analysis known as “Recurrent World Fashions Facilitate Coverage Evolution,” through which they demonstrated the facility of increasing setting modeling previous mere dynamics, as an alternative modeling a compressed spatiotemporal latent illustration of the setting itself utilizing the mixture of a convolutional variational autoencoder (CVAE) and a big RNN, collectively forming the so-called “world mannequin.” The coverage is educated fully throughout the representations of this world mannequin, and since it’s by no means uncovered to the true setting, a dependable world mannequin will be sampled from to simulate imaginary rollouts from its discovered understanding of the world, supplying efficient artificial examples for additional coaching of the coverage. This makes coverage coaching way more information environment friendly, which is a large benefit for sensible functions of RL in actual world domains for which information assortment and labeling is resource-intensive.

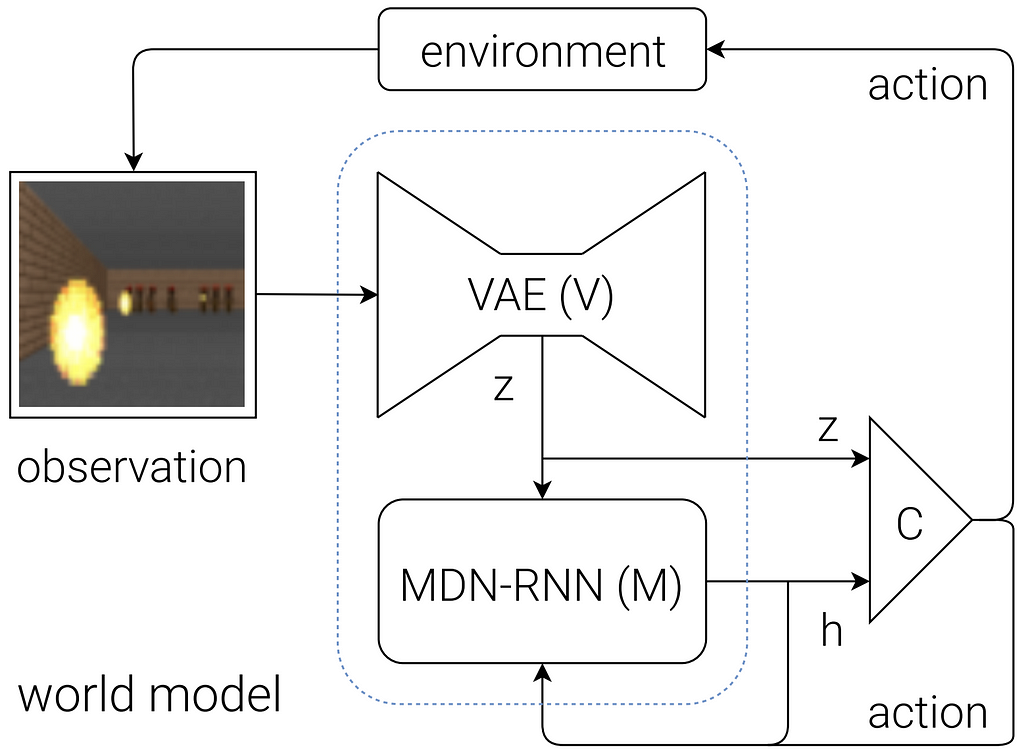
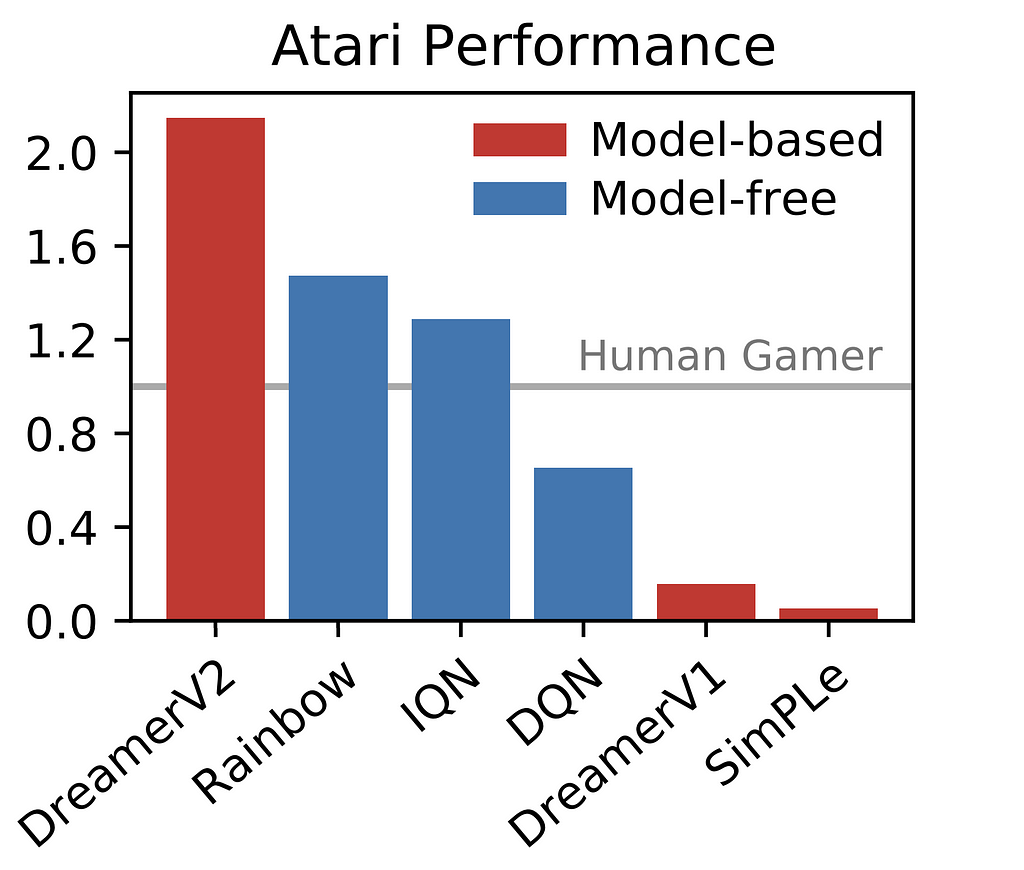
This engaging idea of studying within the creativeness of world fashions has since caught on. Simulated Coverage Studying (SimPLe) took benefit of this paradigm to coach a PPO coverage inside a video prediction mannequin to attain cutting-edge in Atari video games utilizing solely two hours of real-time gameplay expertise. DreamerV2 (an enchancment on Dreamer) turned the primary instance of an agent discovered in creativeness to attain superhuman efficiency on the Atari 50M benchmark (though requiring months of gameplay expertise). The Dreamer algorithm additionally proved to be efficient for on-line studying of actual robotics management within the type of DayDreamer.
Though they initially proved difficult to coach in RL settings, the alluring qualities of transformers invited their disruptive results into one more analysis subject. There are a number of advantages to framing RL as a sequence modeling drawback, particularly the simplification of structure and drawback formulation, and the scalability of the info and mannequin measurement supplied by transformers. Trajectory Transformer is educated to foretell future states, rewards, and actions, however is restricted to low-dimensional states, whereas Determination Transformer can deal with picture inputs however solely predicts actions.
Posing reinforcement studying, and extra broadly data-driven management, as a sequence modeling drawback handles lots of the issues that usually require distinct options: actor-critic algorithms…estimation of the conduct coverage…dynamics fashions…worth features. All of those issues will be unified underneath a single sequence mannequin, which treats states, actions, and rewards as merely a stream of information. The benefit of this attitude is that high-capacity sequence mannequin architectures will be delivered to bear on the issue, leading to a extra streamlined strategy that might profit from the identical scalability underlying large-scale unsupervised studying outcomes.
— Motivation offered within the introduction to Trajectory Transformer
IRIS (Creativeness with auto-Regression over an Internal Speech) is a current open-source venture which builds a generative world mannequin that’s related in construction to VQGAN and DALL-E, combining a discrete autoencoder with a GPT-style autoregressive transformer. IRIS learns conduct by simulating hundreds of thousands of trajectories, utilizing encoded picture tokens and coverage actions as inputs to the transformer to foretell the following set of picture tokens, rewards, and episode termination standing. The anticipated picture tokens are decoded into a picture which is handed to the coverage to generate the following motion, though the authors concede that coaching the coverage on the latent area might end in higher efficiency.
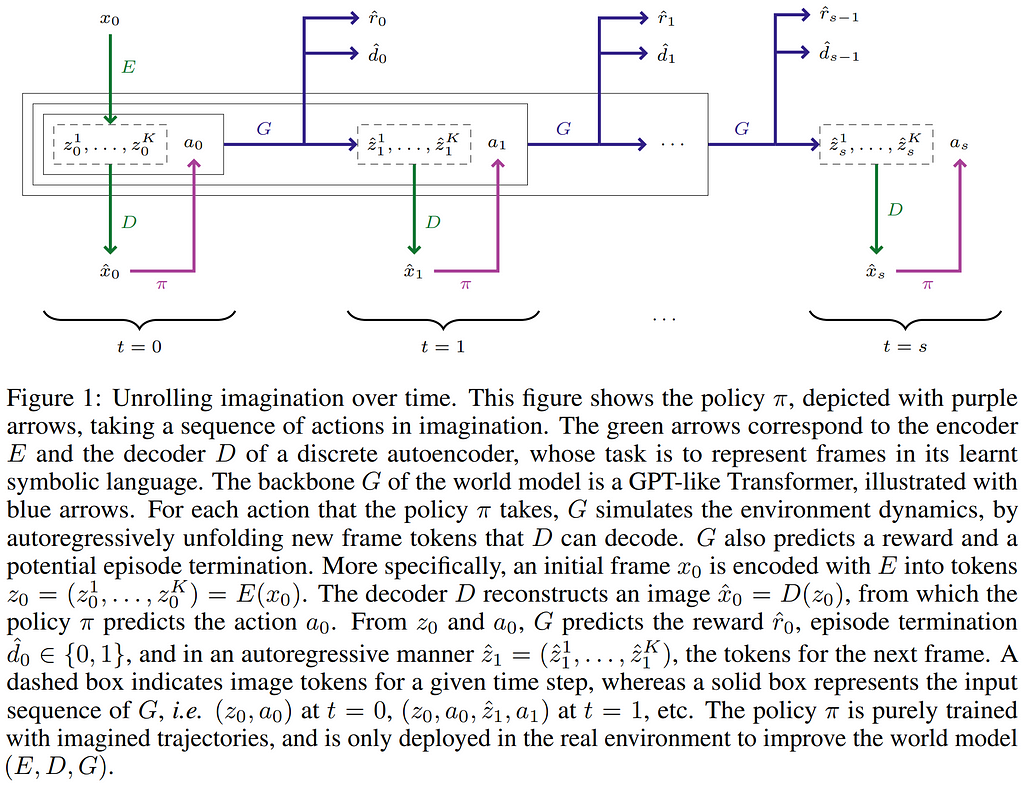

GAIA-1 by Wayve takes the autoregressive transformer world modeling strategy to the following degree by incorporating picture and video era utilizing a diffusion decoder, in addition to including textual content conditioning as an enter modality. This permits pure language steerage of the video era at inference time, permitting for prompting particular situations just like the presence of climate or agent behaviors such because the automobile straying from its lane. Nonetheless, GAIA-1 is restricted to picture and video output, and future work ought to examine multimodality within the output in order that the mannequin can clarify what it sees and the actions it’s taking, which has the potential to invalidate criticisms that end-to-end driving stacks are uninterpretable. Moreover, GAIA-1 generates motion tokens within the latent area, however these will not be decoded. Decoding these actions from the latent area would enable utilizing the mannequin for robotic management and enhance interpretability. Additional, the rules of ImageBind may very well be utilized to increase the enter information modalities (i.e. together with depth) to doubtlessly develop a extra common inner world illustration and higher downstream era.

Within the context of those developments in world fashions, it’s necessary to acknowledge the potential disruptive influence of generative fashions like GAIA-1 on the sector of artificial information era. As these superior fashions turn out to be more proficient at creating sensible, various datasets, they may revolutionize the best way artificial information is produced. At present, the dominant strategy to automotive artificial information era is to make use of simulation and physically-based rendering, usually inside a sport engine, to generate scenes with full management over the climate, map, and brokers. Synscapes is a seminal work in any such artificial dataset era, the place the authors discover the advantages of engineering the info era course of to match the goal area as intently as doable in combating the deleterious results of the synthetic-to-real area hole on data switch.
Whereas progress has been made in quite a few methods to handle it, this synthetic-to-real area hole is an artifact of the artificial information era course of and presents an ongoing problem within the transferability of data between domains, blocking the complete potential of studying from simulation. Sampling artificial information from a world mannequin, nonetheless, is a essentially completely different strategy and compelling various. Any positive factors within the mannequin’s descriptive capability and environmental data will mutually profit the standard of artificial information produced by the mannequin. This artificial information is sampled instantly from the mannequin’s discovered distribution, decreasing any considerations over distribution alignment to be between the mannequin and the area being modeled, fairly than involving a 3rd area that’s affected by a very completely different set of forces. As generative fashions proceed to enhance, it’s conceivable that any such artificial information era will supersede the advanced and essentially disjoint era technique of at present.
Navigating the Future: Multi-Job vs. Massive World Fashions in Autonomous Programs
The panorama of autonomous navigation is witnessing an intriguing evolution in approaches to scene understanding, formed by developments in each multi-task imaginative and prescient fashions and huge world fashions. My very own work, together with that of others within the subject, has efficiently leveraged multi-task fashions in notion modules, demonstrating their efficacy and effectivity. Concurrently, firms like Wayve are pioneering using massive world fashions in autonomy, signaling a possible paradigm shift.
The compactness and information effectivity of multi-task imaginative and prescient fashions make them a pure selection to be used in notion modules. By dealing with a number of imaginative and prescient duties concurrently, they provide a practical answer throughout the conventional modular autonomy stack. Nonetheless, on this design paradigm, such notion modules should be mixed with downstream planning and management modules to attain autonomous operation. This creates a sequence of advanced parts performing extremely specialised drawback formulations, a construction which is of course susceptible to compounding error. The power of every module to carry out nicely is determined by the standard of data it receives from the earlier hyperlink on this daisy-chained design, and errors showing early on this pipeline are more likely to get amplified.
Whereas works like Nvidia’s DiffStack construct in direction of differentiable loss formulations able to backprop via distinct job modules to supply a best-of-both-worlds answer that’s each learnable and interpretable by people, the periodic crystallization of middleman, human-interpretable information representations between modules is inherently a type of lossy compression that creates info bottlenecks. Additional, chaining collectively a number of fashions accumulates their respective limitations in representing the world.
Then again, using LMMs as world fashions, illustrated by Wayve’s AV2.0 initiative, suggests a distinct trajectory. These fashions, characterised by their huge parameter areas, suggest an end-to-end framework for autonomy, encompassing notion, planning, and management. Whereas their immense measurement poses challenges for coaching and deployment, current developments are mitigating these points and making using massive fashions extra accessible.
As we glance towards the longer term, it’s evident that the limitations to coaching and deploying massive fashions are steadily diminishing. This ongoing progress within the subject of AI is subtly but considerably altering the dynamics between conventional task-specific fashions and their bigger counterparts. Whereas multi-task imaginative and prescient fashions presently maintain a bonus in sure facets like measurement and deployability, the continuous developments in massive mannequin coaching strategies and computational effectivity are steadily leveling the taking part in subject. As these limitations proceed to be lowered, we might witness a shift in desire in direction of extra complete and built-in fashions.
Bringing Fireplace to Mankind: Democratizing Massive Fashions

Regardless of their spectacular capabilities, massive fashions pose vital challenges. The computational assets required for coaching are immense, elevating considerations about environmental influence and accessibility, and making a barrier to entry for analysis and improvement. Happily, there are a number of instruments which can assist us to deliver the facility of huge basis fashions (LFMs) right down to earth: pruning, quantization, data distillation, adapter modules, low-rank adaptation, sparse consideration, gradient checkpointing, combined precision coaching, and open-source parts. This toolbox supplies us with a promising recipe for concentrating the facility obtained from massive mannequin coaching right down to manageable scales.
One intuitive strategy is to coach a big mannequin to convergence, take away the parameters which have minimal contribution to efficiency, then fine-tune the remaining community. This strategy to community minimization through removing of unimportant weights to cut back the dimensions and inference value of neural networks is named “pruning,” and goes again to the Eighties (see “Optimum Mind Injury” by LeCun et al., 1989). In 2017, researchers at Nvidia offered an influential technique for community pruning which makes use of a Taylor enlargement to estimate the change in loss operate attributable to eradicating a given neuron, offering a metric for its significance, and thus serving to to determine which neurons will be pruned with the least influence on community efficiency. The pruning course of is iterative, with a spherical of fine-tuning carried out between every discount in parameters, and repeated till the specified trade-off of accuracy and effectivity is reached.
Concurrently in 2017, researchers from Google launched a seminal work in community quantization, offering an orthogonal technique for shrinking the dimensions of huge pretrained fashions. The authors offered an influential 8-bit quantization scheme for each weights and activations (full with coaching and inference frameworks) that was geared toward rising inference pace on cell CPUs by utilizing integer-arithmetic-only inference. This type of quantization has been utilized to LLMs to permit them to suit and carry out inference on smaller {hardware} (see the plethora of quantized fashions supplied by TheBloke on the Hugging Face hub).
One other technique for condensing the capabilities of huge, cumbersome fashions is data distillation. It was in 2006 that researchers at Cornell College launched the idea that may later come to be referred to as data distillation in a piece they known as “Mannequin Compression.” This work efficiently explored the idea of coaching small and compact fashions to approximate the features discovered by massive cumbersome consultants (notably massive ensembles). The authors use these massive consultants to supply labels for big unlabeled datasets in numerous domains, and show that smaller fashions educated on the ensuing labeled dataset carried out higher than equal fashions educated on the unique coaching set for the duty at hand. Furthermore, they practice the small mannequin to focus on the uncooked logits produced by the massive mannequin, since their relative values comprise far more info than the both the arduous class labels or the softmax chances, the latter of which compresses particulars and gradients on the low finish of the chance vary.
Hinton et al. expanded on this idea and coined the time period “distillation” in 2015 with “Distilling Data in a Neural Community,” coaching the small mannequin to focus on the possibilities produced by the massive skilled fairly than the uncooked logits, however rising the temperature parameter within the ultimate softmax layer to supply “a suitably mushy set of targets.” The authors set up that this parameter supplies an adjustable degree of amplification for the fine-grained info on the low finish of the chance vary, and discover that fashions with much less capability work higher with decrease temperatures to filter out a few of the element on the far low finish of the logit values to focus the mannequin’s restricted capability on higher-level interactions. They additional show that utilizing their strategy with the unique coaching set fairly than a brand new massive switch dataset nonetheless labored nicely.
High-quality-tuning massive fashions on information generated by different massive fashions can also be a type of data distillation. Self-Instruct proposed an information pipeline for utilizing a LLM to generate instruction tuning information, and whereas the unique paper demonstrated fine-tuning GPT-3 by itself outputs, Alpaca used this strategy to fine-tune LLaMA utilizing ouptuts from GPT-3.5. WizardLM expanded on the Self-Instruct strategy by introducing a technique to regulate the complexity degree of the generated directions known as Evol-Instruct. Vicuna and Koala used actual human/ChatGPT interactions sourced from ShareGPT for instruction tuning. In Orca, Microsoft Analysis warned that whereas smaller fashions educated to mimic the outputs of LFMs might be taught to imitate the writing model of these fashions, they usually fail to seize the reasoning expertise that generated the responses. Happily, their staff discovered that utilizing system directions (e.g. “assume step-by-step and justify your response”) when producing examples with the intention to coax the instructor into explaining its reasoning as a part of the responses supplies the smaller mannequin with an efficient window into the thoughts of the LFM. Orca 2 then launched immediate erasure to compel the smaller fashions to be taught the suitable reasoning technique for a given instruction.
The strategies described above all concentrate on condensing the facility of a big pretrained fashions right down to manageable scales, however what concerning the accessible fine-tuning of those massive fashions? In 2017, Rebuffi et al. launched the facility of adapter modules for mannequin fine-tuning. These are small trainable matrices that may be inserted into pretrained and frozen laptop imaginative and prescient fashions to adapt them to new duties and domains rapidly with few examples. Two years later, Houlsby et al. demonstrated using these adapters in NLP to switch a pretrained BERT mannequin to 26 various pure language classification duties, reaching close to state-of-the-art efficiency. Adapters allow the parameter-efficient fine-tuning of LFMs, and will be simply interchanged to change between the ensuing consultants, fairly than needing a completely completely different mannequin for every job, which might be prohibitively costly to coach and deploy.
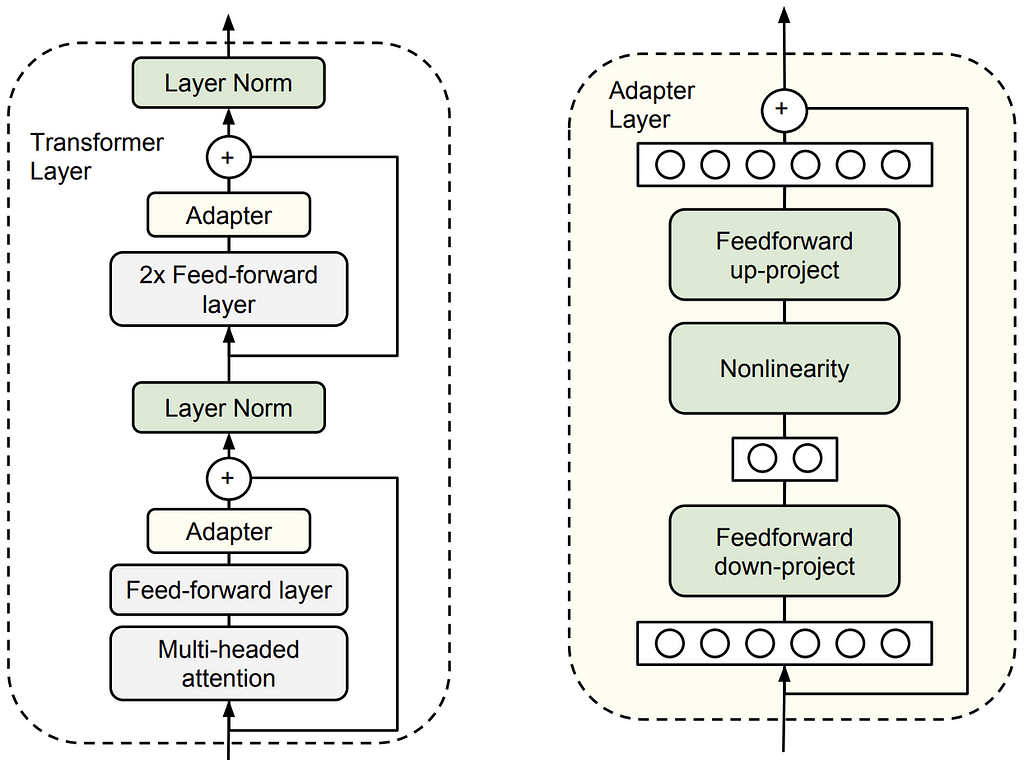
In 2021, Microsoft analysis improved on this idea, introducing a groundbreaking strategy for coaching a brand new type of adapters with Low-Rank Adaptation (LoRA). Relatively than insert adapter matrices into the mannequin like bank cards, which slows down the mannequin’s inference pace, this technique learns weight delta matrices which will be mixed with the frozen weights at inference time, offering a light-weight adapter for switching a base mannequin between fine-tuned duties with none added inference latency. They cut back the variety of trainable parameters by representing the burden delta matrix with a low-rank decomposition into two smaller matrices A and B (whose dot product takes the unique weight matrix form), motivated by their speculation (impressed by Aghajanyan et al., 2020) that the updates to the weights throughout fine-tuning have a low intrinsic rank.

Sparse Transformer additional explores rising the computational effectivity of transformers via two varieties of factorized self-attention. Notably, the authors additionally make use of gradient checkpointing, a resource-poor technique for coaching massive networks by re-computing activations throughout backpropagation fairly than storing them in reminiscence. This technique is particularly efficient for transformers modeling lengthy sequences, since this state of affairs has a comparatively massive reminiscence footprint given its value to compute. This provides a beautiful commerce: a tolerable lower in iteration pace for a considerable discount in GPU footprint throughout coaching, permitting for coaching extra transformer layers on longer sequence lengths than would in any other case be doable given any degree of {hardware} restraints. To extend effectivity additional, Sparse Transformer additionally makes use of combined precision coaching, the place the community weights are saved as single precision floats, however the activations and gradients are computed in half-precision. This additional reduces the reminiscence footprint throughout coaching, and will increase the trainable mannequin measurement on a given {hardware} finances.
Lastly, a serious (and maybe considerably apparent) instrument for democratizing the event and software of huge fashions is the discharge and utilization of pretrained open-source parts. CLIP, the ever present workhorse from OpenAI, is open-source with a commercially permissible license, as is LLaMA 2, the groundbreaking LFM launch from Meta. Pretrained, open-source parts like these consolidate many of the heavy lifting concerned in creating LMMs, since these fashions generalize rapidly to new duties with fine-tuning, which we all know is possible because of the contributions listed above. Notably, NExT-GPT constructed their all-to-all LMM utilizing nothing however obtainable pretrained parts and intelligent alignment studying strategies that solely required coaching projections on the inputs and outputs of the transformer (1% of the entire mannequin weights). So long as the biggest outfits keep their commitments to open-source philosophy, smaller groups will proceed to have the ability to effectively make profound contributions.
As we’ve seen, regardless of the grand scale of the massive fashions, there are a variety of complementary approaches that may be utilized for his or her accessible fine-tuning and deployment. We are able to compress these fashions by distilling their data into smaller fashions and quantizing their weights into integers. We are able to effectively fine-tune them utilizing adapters, gradient checkpointing, and combined precision coaching. Open-source contributions from massive analysis outfits proceed at a decent tempo, and seem like closing the hole with closed-source capabilities. On this local weather, making the shift from conventional drawback formulations into the would of huge sequence modeling is way from a dangerous guess. A current and illustrative success story on this regard is LaVIN, which transformed a frozen LLaMA right into a LMM utilizing light-weight adapters with solely 3.8M parameters educated for 1.4 hours, difficult the efficiency of LLaVA with out requiring any end-to-end high-quality tuning.
Synergizing Various AI Approaches: Combining Multi-Job and Massive World Fashions
Whereas LMMs supply unified options for autonomous navigation and threaten the dominant paradigm of modular AV stacks, they’re additionally essentially modular underneath the hood, and the legacy of MTL will be seen cited in LMM analysis because the begin. The spirit is actually the identical: seize a deep and common data in a central community, and use task-specific parts to extract the related data for a selected job. In some ways, LMM analysis is an evolution of MTL. It shares the identical visionary objective of creating usually succesful fashions, and marks the following main stride in direction of AGI. Unsurprisingly then, the fingerprints of MTL are discovered all through LMM design.
In fashionable LMMs, enter information modalities are individually encoded into the joint embedding area earlier than being handed via the language mannequin, so there may be flexibility in experimenting with these encoders. For instance, the CLIP picture encoders utilized in many LMMs are usually made with ViT-L (307M parameters), and little work has been finished to experiment with different choices. One contender may very well be the PVTv2-B5, which has solely 82M parameters and scores simply 1.5% decrease on the ImageNet benchmark than the ViT-L. It’s extremely doable that hierarchical transformers like PVTv2 might create variations of language-image aligned picture encoders that had been efficient with far fewer parameters, decreasing the general measurement of LMMs considerably.
Equally, there may be room for making use of the teachings of MTL in decoder designs for output information modalities supplied by the LMM. For example, the decoders utilized in Multiformer are very light-weight, however in a position to extract correct depth, semantic segmentation, and object detection from the joint function area. Making use of their design rules to the decoding facet of a LMM might yield output in these modalities, which can be supervised to construct a deeper and extra generalized data within the central embedding area.
Then again, NExT-GPT confirmed the feasibility and strengths of including information modalities like depth on the enter facet of LMMs, so encoding correct multi-task inference from a mannequin like Multiformer into the LMM inputs is an attention-grabbing route for future analysis. It’s doable {that a} well-trained and generalizable skilled might generate high quality pseudo-labels for these further modalities, avoiding the necessity for labeled information when coaching the LMM, however nonetheless permitting the mannequin to align the embedding area with dependable representations of the modalities.
In any case, the transition into LMMs in autonomous navigation is way from a hostile takeover. The teachings discovered from many years of MTL and RL analysis have been given an thrilling new playground on the forefront of AI analysis. AV firms have spent huge quantities on labeling their uncooked information, and lots of are possible sitting on huge troves of sequential, unlabeled information excellent for the self-supervised world modeling job. Given the revelations mentioned on this article, I hope they’re wanting into it.
Conclusion
On this article, we’ve seen the daybreak of a paradigm shift in AV improvement that, by advantage of its advantages, might threaten to displace modular driving stacks because the dominant strategy within the subject. This new strategy of AV2.0 employs LMMs in a sequential world modeling job, predicting future states conditioned on earlier sensor information and management actions, in addition to different modalities like textual content, thereby offering a synthesis of notion, planning, and management in a simplified drawback assertion and unified structure. Beforehand, end-to-end approaches had been seen by many to be an excessive amount of of a black field for safety-critical deployments, as their interior states and determination making processes had been uninterpretable. Nonetheless, with LMMs making driving choices primarily based on sensor information, there may be potential for the mannequin to elucidate what it’s perceiving and the reasoning behind its actions in pure language if prompted to take action. Such a mannequin can even be taught from artificial examples sampled from its personal creativeness, decreasing the necessity for actual world information assortment.
Whereas the potential on this strategy is alluring, it requires very massive fashions to be efficient, and thus inherits their limitations and challenges. Only a few outfits have the assets to coach or fine-tune the complete weight matrix of a multi-billion parameter LLM, and huge fashions include quite a lot of effectivity considerations from the price of compute to the dimensions of embedded {hardware}. Nonetheless, we’ve seen that there are a variety of highly effective open-source instruments and LFMs licensed for business use, quite a lot of strategies for parameter-efficient fine-tuning that make customization possible, and compression strategies that make deployment at manageable scales doable. In mild of these items, shying away from the adoption of huge fashions for fixing advanced issues like autonomous robotics hardly appears justifiable, and would ignore the worth in futureproofing techniques with a rising know-how with loads of developmental overhead, fairly than clinging to approaches which can have already peaked.
Nonetheless, small multi-task fashions have an amazing benefit of their comparably miniscule scale, which grants accessibility and ease of experimentation, whereas simplifying a variety of engineering and budgeting choices. Nonetheless, the constraints of task-specific fashions creates a distinct set of challenges, as a result of such fashions should be organized in advanced modular architectures with the intention to fulfill all the essential features in an autonomy stack. This design ends in a sequential circulate of data via notion, prediction, planning, after which lastly to regulate stacks, making a excessive danger for compounding error via all of this sequential componentry, and hindering end-to-end optimization. Additional, whereas the general parameter depend could also be far decrease on this paradigm, the stack complexity is undeniably far larger, because the quite a few parts every contain specialised drawback formulations from their respective fields of analysis, requiring a big staff of extremely expert engineers from various disciplines to take care of and develop.
Massive fashions have proven profound skill to cause about info and generalize to new duties and domains in a number of modalities, one thing that has eluded the sector of deep studying for a very long time. It has lengthy been recognized that fashions educated to carry out duties via supervised studying are extraordinarily brittle when launched to examples from outdoors of their coaching distributions, and that their skill to carry out a single (and even a number of) duties rather well barely deserves the title “intelligence.” Now, after a number of quick years of explosive improvement that makes 2020 look like the bronze age, it could seem that the good white buffalo of AI analysis has made an look, rising first as a property of gargantuan chat bots, and now casually being bestowed with the presents of sight and listening to. This know-how, together with the revolution in robotics that it has begun, appears poised to ship nimble robotic management in a matter of years, if not sooner, and AVs might be one of many first fields to show that energy to the world.
Future Work
As talked about above, the CLIP encoder driving many LMMs is often constituted of a ViT-L, and we’re overdue for experimenting with more moderen architectures. Hierarchical transformers just like the PVTv2 almost match the efficiency of ViT-L on ImageNet with a fraction of the parameters, so they’re possible candidates for serving as language-aligned picture encoders in compact LMMs.
IRIS and GAIA-1 function blueprints for the trail ahead in constructing world fashions with LMMs. Nonetheless, the output modalities for each fashions are restricted. Each fashions use autoregressive transformers to foretell future frames and rewards, however whereas GAIA-1 does enable for textual content prompting, neither of them is designed to generate textual content, which might be an enormous step in evaluating reasoning expertise and decoding fail modes.
At this stage, the sector would tremendously profit from the discharge of an open-source generative world mannequin like GAIA-1, however with an all-to-all modality scheme that gives pure language and actions within the output. This may very well be achieved via the addition of adaptors, encoders, decoders, and a revised drawback assertion. It’s possible that the pretrained parts required to assemble such an structure exist already, and that they may very well be aligned utilizing an affordable variety of trainable parameters, so that is an open lane for analysis.
Additional, as demonstrated with Mixtral 8X7B, MoE configurations of small fashions can prime the efficiency of bigger single fashions, and future work ought to discover MoE configurations for LMM-based world fashions. Additional, distilling a big MoE right into a single mannequin has confirmed to be an efficient technique of mannequin compression, and will possible enhance massive world mannequin efficiency to the following degree, so this supplies further motivation for making a MoE LMM world mannequin.
Lastly, fine-tuning of open-source fashions utilizing artificial information with commercially-permissible licenses ought to turn out to be customary follow. As a result of Vicuna, WizardLM, and Orca are educated utilizing outputs from ChatGPT, these pretrained weights are inherently licensed for analysis functions solely, so whereas these releases supply highly effective methodology for fine-tuning LLMs, they don’t absolutely “democratize” this energy since anybody searching for to make use of fashions created with these strategies for business functions should expend the pure and monetary assets essential to assemble a brand new dataset and repeat the experiment. There needs to be an initiative to generate artificial instruction tuning datasets with strategies like Evol-Instruct utilizing commercially-permissible open-source fashions fairly than ChatGPT in order that weights educated utilizing these datasets are absolutely democratized, serving to to raise these with fewer assets.
Navigating the Future was initially printed in In direction of Knowledge Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.
[ad_2]