
[ad_1]
Diffusion fashions have undoubtedly revolutionized the AI and ML business, with their purposes in real-time turning into an integral a part of our on a regular basis lives. After text-to-image fashions showcased their outstanding skills, diffusion-based picture manipulation strategies, resembling controllable technology, specialised and personalised picture synthesis, object-level picture modifying, prompt-conditioned variations, and modifying, emerged as sizzling analysis subjects as a result of their purposes within the laptop imaginative and prescient business.
Nevertheless, regardless of their spectacular capabilities and distinctive outcomes, text-to-image frameworks, significantly text-to-image inpainting frameworks, nonetheless have potential areas for growth. These embody the flexibility to grasp world scenes, particularly when denoising the picture in excessive diffusion timesteps. Addressing this subject, researchers launched HD-Painter, a very training-free framework that precisely follows immediate directions and scales to high-resolution picture inpainting coherently. The HD-Painter framework employs a Immediate Conscious Introverted Consideration (PAIntA) layer, which leverages immediate data to reinforce self-attention scores, leading to higher textual content alignment technology.
To additional enhance the coherence of the immediate, the HD-Painter mannequin introduces a Reweighting Consideration Rating Steering (RASG) strategy. This strategy integrates a post-hoc sampling technique into the final type of the DDIM element seamlessly, stopping out-of-distribution latent shifts. Moreover, the HD-Painter framework contains a specialised super-resolution method custom-made for inpainting, permitting it to increase to bigger scales and full lacking areas within the picture with resolutions as much as 2K.
HD-Painter: Textual content-Guided Picture Inpainting
Textual content-to-image diffusion fashions have certainly been a big subject within the AI and ML business in latest months, with fashions demonstrating spectacular real-time capabilities throughout numerous sensible purposes. Pre-trained text-to-image technology fashions like DALL-E, Imagen, and Secure Diffusion have proven their suitability for picture completion by merging denoised (generated) unknown areas with subtle identified areas throughout the backward diffusion course of. Regardless of producing visually interesting and well-harmonized outputs, current fashions wrestle to grasp the worldwide scene, significantly underneath the excessive diffusion timestep denoising course of. By modifying pre-trained text-to-image diffusion fashions to include extra context data, they are often fine-tuned for text-guided picture completion.
Moreover, inside diffusion fashions, text-guided inpainting and text-guided picture completion are main areas of curiosity for researchers. This curiosity is pushed by the truth that text-guided inpainting fashions can generate content material in particular areas of an enter picture primarily based on textual prompts, resulting in potential purposes resembling retouching particular picture areas, modifying topic attributes like colours or garments, and including or changing objects. In abstract, text-to-image diffusion fashions have just lately achieved unprecedented success, as a result of their exceptionally reasonable and visually interesting technology capabilities.

Nevertheless, a majority of current frameworks exhibit immediate neglection in two eventualities. The primary is Background Dominance when the mannequin completes the unknown area by ignoring the immediate within the background whereas the second state of affairs is close by object dominance when the mannequin propagates the identified area objects to the unknown area utilizing visible context probability somewhat than the enter immediate. It’s a risk that each these points may be a results of vanilla inpainting diffusion’s means to interpret the textual immediate precisely or combine it with the contextual data obtained from the identified area.
To deal with these roadblocks, the HD-Painter framework introduces the Immediate Conscious Introverted Consideration or PAIntA layer, that makes use of immediate data to reinforce the self-attention scores that finally leads to higher textual content alignment technology. PAIntA makes use of the given textual conditioning to reinforce the self consideration rating with the purpose to scale back the affect of non-prompt related data from the picture area whereas on the similar time rising the contribution of the identified pixels aligned with the immediate. To additional improve the text-alignment of the generated outcomes, the HD-Painter framework implements a post-hoc steering methodology that leverages the cross-attention scores. Nevertheless, the implementation of the vanilla post-hoc steering mechanism may trigger out of distribution shifts because of the extra gradient time period within the diffusion equation. The out of distribution shift will finally lead to high quality degradation of the generated output. To deal with this roadblock, the HD-Painter framework implements a Reweighting Consideration Rating Steering or RASG, a way that integrates a post-hoc sampling technique into the final type of the DDIM element seamlessly. It permits the framework to generate visually believable inpainting outcomes by guiding the pattern in the direction of the prompt-aligned latents, and include them of their educated area.
By deploying each the RASH and PAIntA elements in its structure, the HD-Painter framework holds a big benefit over current, together with cutting-edge, inpainting, and textual content to picture diffusion fashions as a result of it manages to unravel the present subject of immediate neglection. Moreover, each the RASH and the PAIntA elements supply plug and play performance, permitting them to be appropriate with diffusion base inpainting fashions to deal with the challenges talked about above. Moreover, by implementing a time-iterative mixing know-how and by leveraging the capabilities of high-resolution diffusion fashions, the HD-Painter pipeline can function successfully for as much as 2K decision inpainting.
To sum it up, the HD-Painter goals to make the next contributions within the area:
- It goals to resolve the immediate neglect subject of the background and close by object dominance skilled by text-guided picture inpainting frameworks by implementing the Immediate Conscious Introverted Consideration or PAIntA layer in its structure.
- It goals to enhance the text-alignment of the output by implementing the Reweighting Consideration Rating Steering or RASG layer in its structure that allows the HD-Painter framework to carry out post-hoc guided sampling whereas stopping out of shift distributions.
- To design an efficient training-free text-guided picture completion pipeline able to outperforming the present cutting-edge frameworks, and utilizing the easy but efficient inpainting-specialized super-resolution framework to carry out text-guided picture inpainting as much as 2K decision.
HD-Painter: Technique and Structure
Earlier than we take a look on the structure, it is important to grasp the three basic ideas that type the inspiration of the HD-Painter framework: Picture Inpainting, Submit-Hoc Steering in Diffusion Frameworks, and Inpainting Particular Architectural Blocks.
Picture Inpainting is an strategy that goals to fill the lacking areas inside a picture whereas guaranteeing the visible enchantment of the generated picture. Conventional deep studying frameworks applied strategies that used identified areas to propagate deep options. Nevertheless, the introduction of diffusion fashions has resulted within the evolution of inpainting fashions, particularly the text-guided picture inpainting frameworks. Historically, a pre-trained textual content to picture diffusion mannequin replaces the unmasked area of the latent through the use of the noised model of the identified area throughout the sampling course of. Though this strategy works to an extent, it degrades the standard of the generated output considerably for the reason that denoising community solely sees the noised model of the identified area. To deal with this hurdle, a number of approaches aimed to fine-tune the pre-trained textual content to picture mannequin to realize text-guided picture inpainting. By implementing this strategy, the framework is ready to generate a random masks by way of concatenation for the reason that mannequin is ready to situation the denoising framework on the unmasked area.
Shifting alongside, the standard deep studying fashions applied particular design layers for environment friendly inpainting with some frameworks with the ability to extract data successfully and produce visually interesting pictures by introducing particular convolution layers to take care of the identified areas of the picture. Some frameworks even added a contextual consideration layer of their structure to scale back the undesirable heavy computational necessities of all to all self consideration for top of the range inpainting.
Lastly, the Submit-hoc steering strategies are backward diffusion sampling strategies that information the following step latent prediction in the direction of a specific perform minimization goal. Submit-hoc steering strategies are of nice assist with regards to producing visible content material particularly within the presence of extra constraints. Nevertheless, the Submit-hoc steering strategies have a significant downside: they’re identified to lead to picture high quality degradations since they have an inclination to shift the latent technology course of by a gradient time period.
Coming to the structure of HD-Painter, the framework first formulates the text-guided picture completion drawback, after which introduces two diffusion fashions particularly the Secure Inpainting and Secure Diffusion. The HD-Painter mannequin then introduces the PAIntA and the RASG blocks, and at last we arrive on the inpainting-specific tremendous decision method.
Secure Diffusion and Secure Inpainting
Secure Diffusion is a diffusion mannequin that operates throughout the latent area of an autoencoder. For textual content to picture synthesis, the Secure Diffusion framework implements a textual immediate to information the method. The guiding perform has a construction just like the UNet structure, and the cross-attention layers situation it on the textual prompts. Moreover, the Secure Diffusion mannequin can carry out picture inpainting with some modifications and fine-tuning. To realize so, the options of the masked picture generated by the encoder is concatenated with the downscaled binary masks to the latents. The ensuing tensor is then enter into the UNet structure to acquire the estimated noise. The framework then initializes the newly added convolutional filters with zeros whereas the rest of the UNet is initialized utilizing pre-trained checkpoints from the Secure Diffusion mannequin.

The above determine demonstrates the overview of the HD-Painter framework consisting of two levels. Within the first stage, the HD-Painter framework implements text-guided picture portray whereas within the second stage, the mannequin inpaints particular super-resolution of the output. To fill within the mission areas and to stay according to the enter immediate, the mannequin takes a pre-trained inpainting diffusion mannequin, replaces the self-attention layers with PAIntA layers, and implements the RASG mechanism to carry out a backward diffusion course of. The mannequin then decodes the ultimate estimated latent leading to an inpainted picture. HD-Painter then implements the tremendous steady diffusion mannequin to inpaint the unique measurement picture, and implements the diffusion backward technique of the Secure Diffusion framework conditioned on the low decision enter picture. The mannequin blends the denoised predictions with the unique picture’s encoding after every step within the identified area and derives the following latent. Lastly, the mannequin decodes the latent and implements Poisson mixing to keep away from edge artifacts.
Immediate Conscious Introverted Consideration or PAIntA
Current inpainting fashions like Secure Inpainting are inclined to rely extra on the visible context across the inpainting space and ignore the enter consumer prompts. On the idea of the consumer expertise, this subject will be categorized into two lessons: close by object dominance and background dominance. The problem of visible context dominance over the enter prompts may be a results of the only-spatial and prompt-free nature of the self-attention layers. To deal with this subject, the HD-Painter framework introduces the Immediate Conscious Introverted Consideration or PAIntA that makes use of cross-attention matrices and an inpainting masks to manage the output of the self-attention layers within the unknown area.
The Immediate Conscious Introverted Consideration element first applies projection layers to get the important thing, values, and queries together with the similarity matrix. The mannequin then adjusts the eye rating of the identified pixels to mitigate the robust affect of the identified area over the unknown area, and defines a brand new similarity matrix by leveraging the textual immediate.

Reweighting Consideration Rating Steering or RASG
The HD-Painter framework adopts a post-hoc sampling steering methodology to reinforce the technology alignment with the textual prompts even additional. Together with an goal perform, the post-hoc sampling steering strategy goals to leverage the open-vocabulary segmentation properties of the cross-attention layers. Nevertheless, this strategy of vanilla post-hoc steering has the potential to shift the area of diffusion latent which may degrade the standard of the generated picture. To deal with this subject, the HD-Painter mannequin implements the Reweighting Consideration Rating Steering or RASG mechanism that introduces a gradient reweighting mechanism leading to latent area preservation.
HD-Painter : Experiments and Outcomes
To investigate its efficiency, the HD-Painter framework is in contrast in opposition to present cutting-edge fashions together with Secure Inpainting, GLIDE, and BLD or Blended Latent Diffusion over 10000 random samples the place the immediate is chosen because the label of the chosen occasion masks.
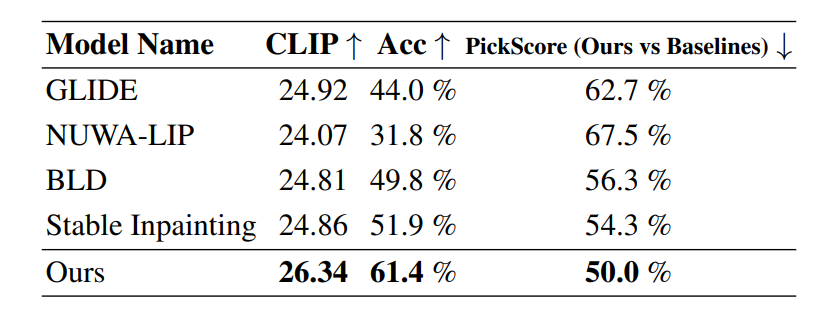
As it may be noticed, the HD-Painter framework outperforms current frameworks on three completely different metrics by a big margin, particularly the advance of 1.5 factors on the CLIP metric and distinction in generated accuracy rating of about 10% from different cutting-edge strategies.

Shifting alongside, the next determine demonstrates the qualitative comparability of the HD-Painter framework with different inpainting frameworks. As it may be noticed, different baseline fashions both reconstruct the lacking areas within the picture as a continuation of the identified area objects disregarding the prompts or they generate a background. Then again, the HD-Painter framework is ready to generate the goal objects efficiently owing to the implementation of the PAIntA and the RASG elements in its structure.

Closing Ideas
On this article, we’ve talked about HD-Painter, a coaching free textual content guided high-resolution inpainting strategy that addresses the challenges skilled by current inpainting frameworks together with immediate neglection, and close by and background object dominance. The HD-Painter framework implements a Immediate Conscious Introverted Consideration or PAIntA layer, that makes use of immediate data to reinforce the self-attention scores that finally leads to higher textual content alignment technology.
To enhance the coherence of the immediate even additional, the HD-Painter mannequin introduces a Reweighting Consideration Rating Steering or RASG strategy that integrates a post-hoc sampling technique into the final type of the DDIM element seamlessly to forestall out of distribution latent shifts. Moreover, the HD-Painter framework introduces a specialised super-resolution method custom-made for inpainting that leads to extension to bigger scales, and permits the HD-Painter framework to finish the lacking areas within the picture with decision as much as 2K.


[ad_2]