
[ad_1]
Abstract: just lately whereas fine-tuning a big language mannequin (LLM) on multiple-choice science examination questions, we noticed some extremely uncommon coaching loss curves. Particularly, it appeared the mannequin was capable of quickly memorize examples from the dataset after seeing them simply as soon as. This astonishing feat contradicts most prior knowledge about neural community pattern effectivity. Intrigued by this outcome, we performed a collection of experiments to validate and higher perceive this phenomenon. It’s early days, however the experiments help the speculation that the fashions are capable of quickly bear in mind inputs. This may imply now we have to re-think how we prepare and use LLMs.
How neural networks study
We prepare neural community classifiers by displaying them examples of inputs and outputs, they usually study to foretell outputs primarily based on inputs. For instance, we present examples of images of canine and cats, together with the breed of every, they usually study to guess the breed from the picture. To be extra exact, for an inventory of attainable breeds, they output their guess as to the chance of every breed. If it’s not sure, it would guess a roughly equal chance of every attainable breed, and if it’s extremely assured, it would guess an almost 1.0 chance of its predicted breed.
The coaching course of consists of each picture in a coaching set being proven to the community, together with the proper label. A cross by means of all of the enter knowledge is known as an “epoch”. We have now to offer many examples of the coaching knowledge for the mannequin to study successfully.
Throughout coaching the neural community makes an attempt to cut back the loss, which is (roughly talking) a measure of how usually the mannequin is flawed, with extremely assured flawed predictions penalised probably the most, and vise versa. We calculate the loss after every batch for the coaching set, and once in a while (usually on the finish of every epoch) we additionally calculated the loss for a bunch of inputs the mannequin does not get to study from – that is the “validation set”. Right here’s what that appears like in follow after we prepare for 11 epochs:
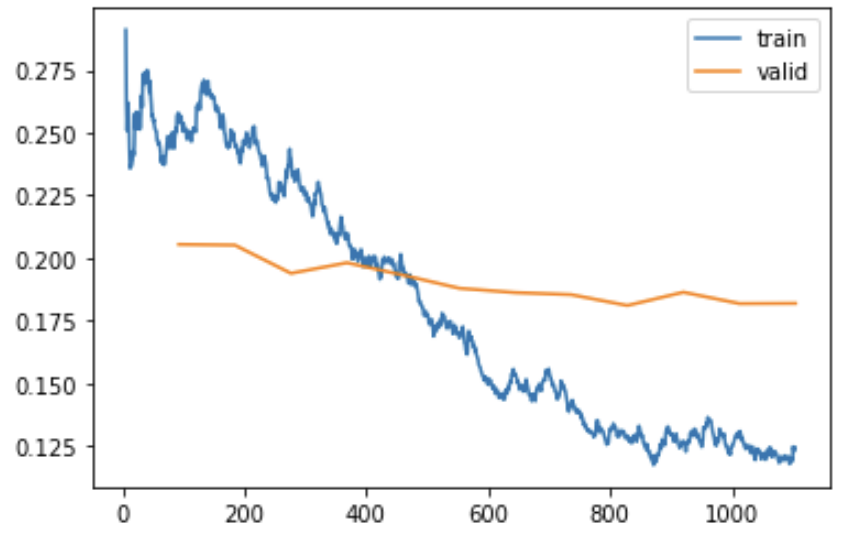
As you see, the coaching loss steadily (and bumpily) improves comparatively shortly, slowing down over time, and the validation loss improves extra slowly (and would ultimately flatten out fully, after which ultimately worsen, if educated for longer).
You may’t see from the chart the place epochs begin and cease, as a result of it takes many epochs earlier than a mannequin learns what any explicit picture seems to be like. This has been a elementary constraint of neural networks all through the many years they’ve been developed – they take an awfully very long time to study something! It’s really an space of energetic analysis about why neural nets are so “pattern inefficient”, particularly in comparison with how youngsters study.
A really odd loss curve
We have now just lately been engaged on the Kaggle LLM Science Examination competitors, which “challenges members to reply troublesome science-based questions written by a Giant Language Mannequin”. As an illustration, right here’s the primary query:
Which of the next statements precisely describes the affect of Modified Newtonian Dynamics (MOND) on the noticed “lacking baryonic mass” discrepancy in galaxy clusters?
- MOND is a principle that reduces the noticed lacking baryonic mass in galaxy clusters by postulating the existence of a brand new type of matter known as “fuzzy darkish matter.”
- MOND is a principle that will increase the discrepancy between the noticed lacking baryonic mass in galaxy clusters and the measured velocity dispersions from an element of round 10 to an element of about 20.
- MOND is a principle that explains the lacking baryonic mass in galaxy clusters that was beforehand thought of darkish matter by demonstrating that the mass is within the type of neutrinos and axions.
- MOND is a principle that reduces the discrepancy between the noticed lacking baryonic mass in galaxy clusters and the measured velocity dispersions from an element of round 10 to an element of about 2.
- MOND is a principle that eliminates the noticed lacking baryonic mass in galaxy clusters by imposing a brand new mathematical formulation of gravity that doesn’t require the existence of darkish matter.
For these enjoying alongside at residence, the proper reply, apparently, is D.
Fortunately, we don’t must depend on our information of Modified Newtonian Dynamics to reply these questions – as a substitute, we’re tasked to coach a mannequin to reply these questions. Once we submit our mannequin to Kaggle, it is going to be examined towards hundreds of “held out” questions that we don’t get to see.
We educated our mannequin for 3 epochs on a large dataset of questions created by our buddy Radek Osmulski, and noticed the next most surprising coaching loss curve:
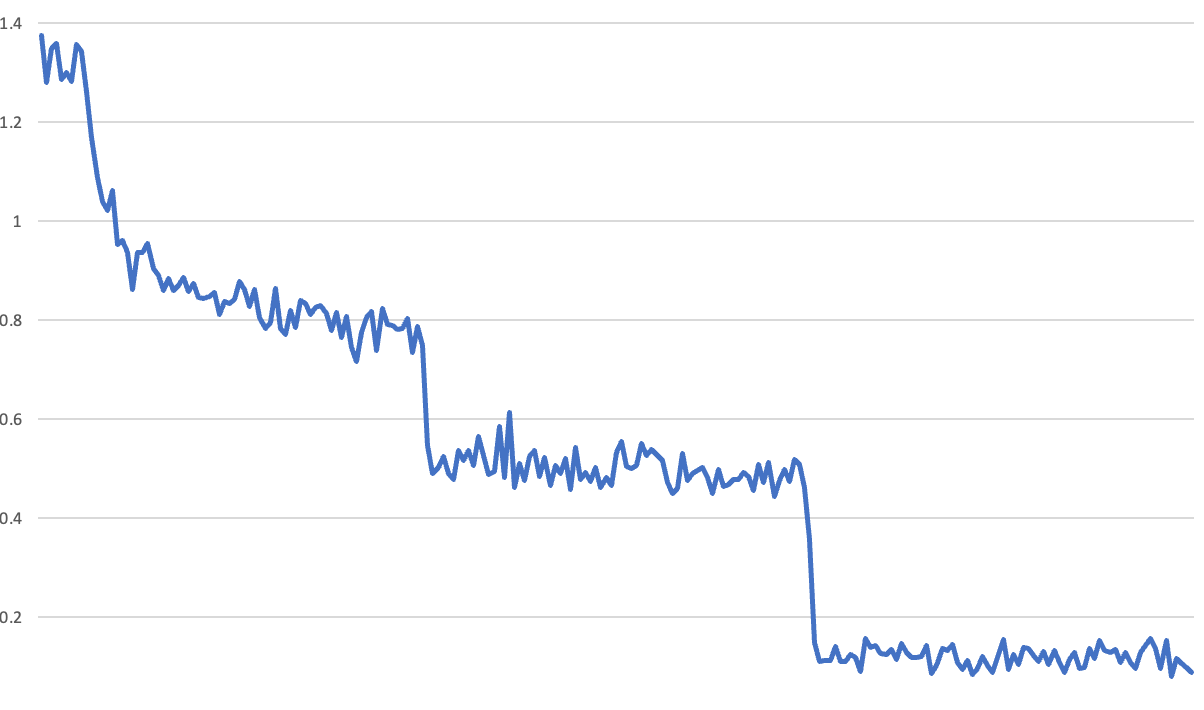
The issue right here is that you may clearly see the top of every epoch – there’s a sudden downwards leap in loss. We’ve seen comparable loss curves earlier than, they usually’ve at all times been as a result of a bug. As an illustration, it’s straightforward to by chance have the mannequin proceed to study when evaluating the validation set – such that after validation the mannequin out of the blue seems significantly better. So we got down to search for the bug in our coaching course of. We have been utilizing Hugging Face’s Coach, so we guessed there have to be a bug in that.
While we started stepping by means of the code, we additionally requested fellow open supply builders on the Alignment Lab AI Discord in the event that they’ve seen comparable odd coaching curves, and just about everybody mentioned “sure”. However everybody who responded was utilizing Coach as properly, which appeared to help our principle of a bug in that library.
However then @anton on Discord informed us he was seeing this curve together with his personal easy customized coaching loop:
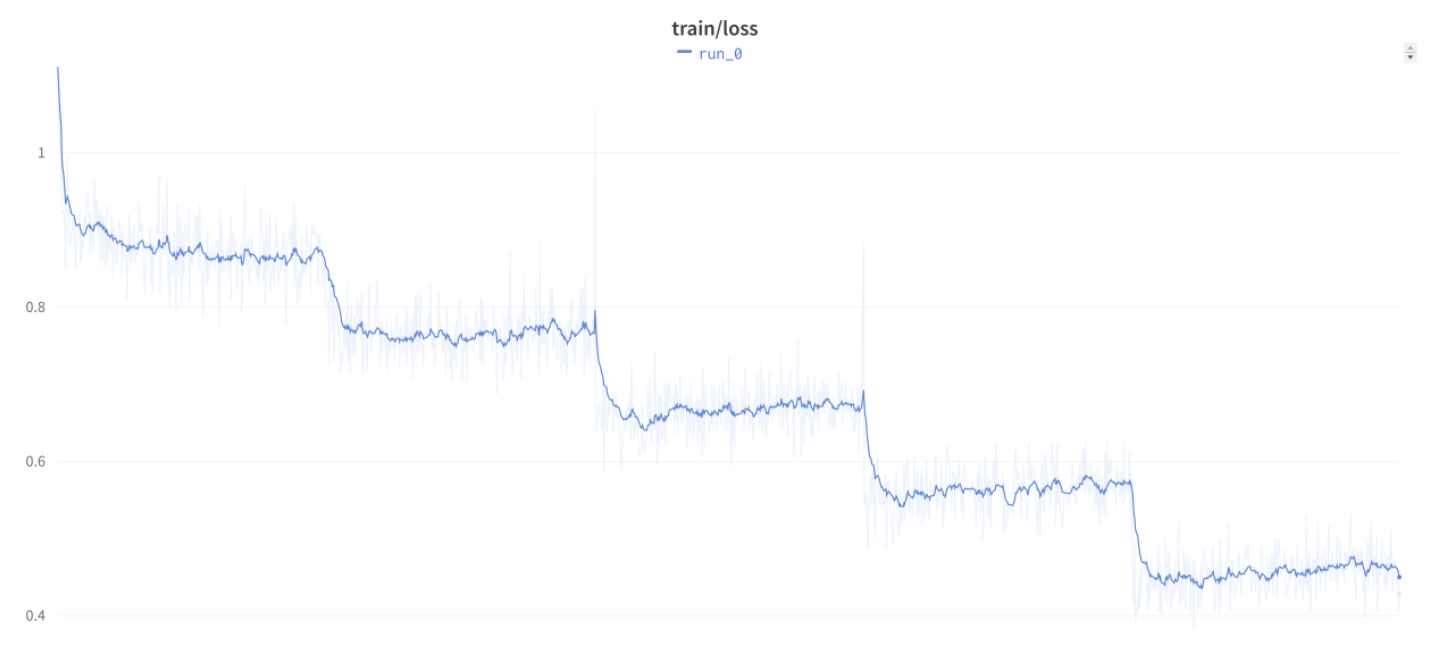
…and he additionally confirmed us this accompanying extraordinarily stunning validation loss curve:
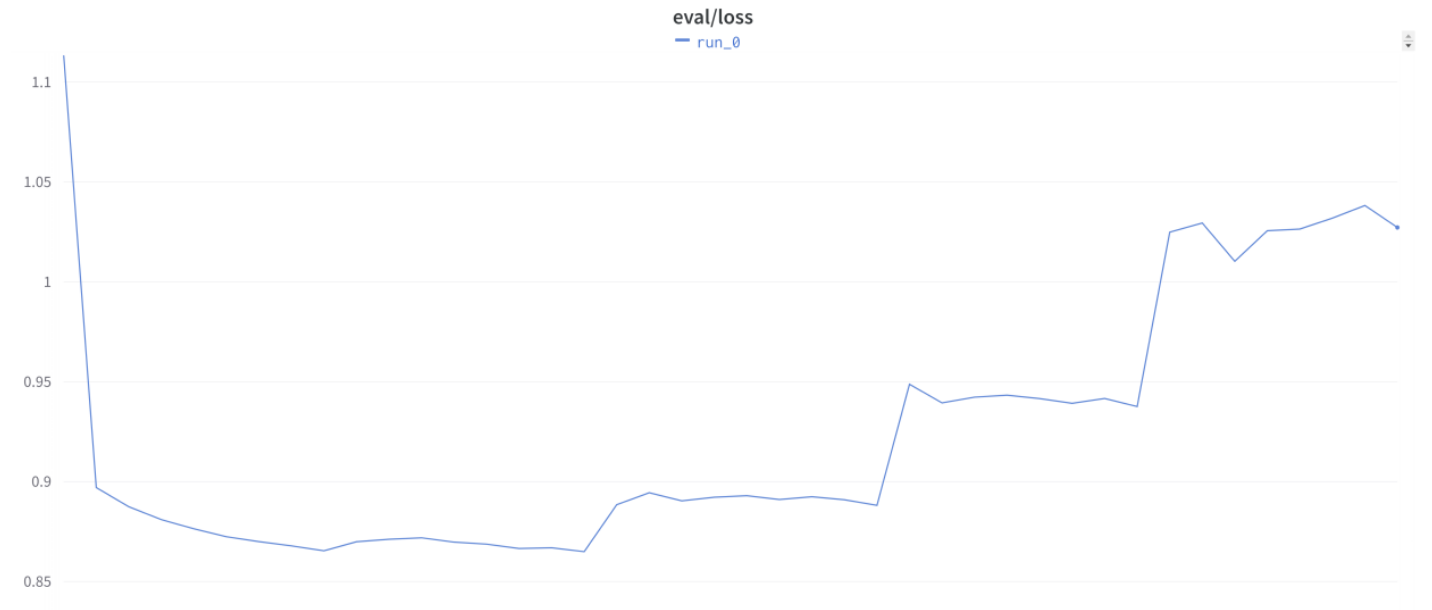
Then we began listening to from increasingly more Discord pals that they’d seen comparable unusual habits, together with when not utilizing Coach. We questioned if it was some oddity particular to the LoRA strategy we have been utilizing, however we heard from of us seeing the identical sample when doing full fine-tuning too. In reality, it was principally widespread information within the LLM fine-tuning group that that is simply how issues go if you’re doing this sort of work!…
Digging deeper
The speculation that we stored listening to from open supply colleagues is that that these coaching curves have been really displaying overfitting. This appeared, at first, fairly not possible. It could indicate that the mannequin was studying to recognise inputs from only one or two examples. For those who look again at that first curve we confirmed, you’ll be able to see the loss diving from 0.8 to 0.5 after the primary epoch, after which from 0.5 to underneath 0.2 after the second. Moreover, throughout every of the second and third epochs it wasn’t actually studying something new in any respect. So, apart from its preliminary studying in the course of the starting of the primary epoch, practically all of the obvious studying was (in line with this principle) memorization of the coaching set occurring with solely 3 examples per row! Moreover, for every query, it solely will get a tiny quantity of sign: how its guess as to the reply in comparison with the true label.
We tried out an experiment – we educated our Kaggle mannequin for 2 epochs, utilizing the next studying price schedule:
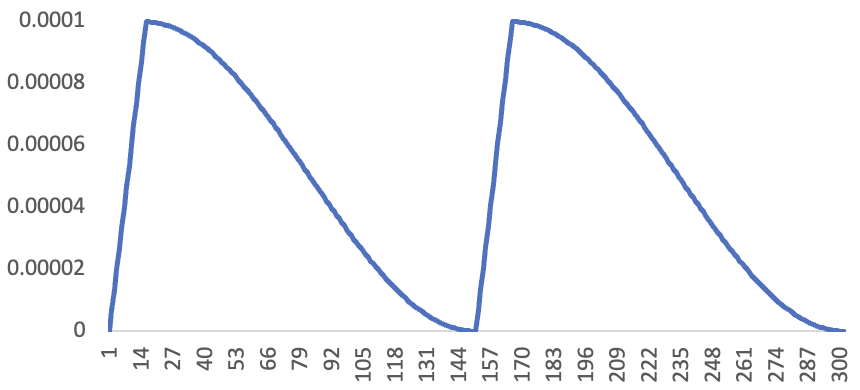
These days this sort of schedule shouldn’t be that widespread, however it’s an strategy that noticed loads of success after it was created by Leslie Smith, who mentioned it in his 2015 paper Cyclical Studying Charges for Coaching Neural Networks.
And right here’s the crazy-looking coaching and validation loss curves we noticed in consequence:
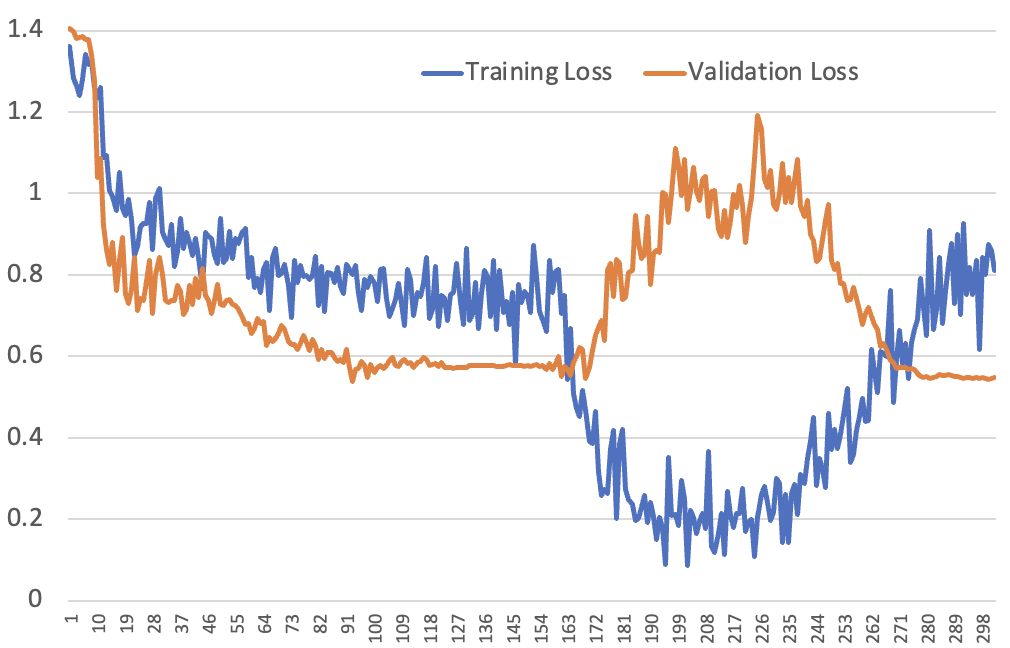
The one factor that now we have give you (to this point!) that absolutely explains this image is that the speculation is appropriate: the mannequin is quickly studying to recognise examples even simply seeing them as soon as. Let’s work by means of every a part of the loss curve in flip…
Wanting on the first epoch, this seems to be like a really commonplace loss curve. We have now the educational price warming up over the primary 10% of the epoch, after which steadily lowering following a cosine schedule. As soon as the LR comes as much as temperature, the coaching and validation loss quickly lower, after which they each decelerate because the LR decreases and the “fast wins” are captured.
The second epoch is the place it will get . We’re not re-shuffling the dataset at first of the epoch, so these first batches of the second epoch are when the educational price was nonetheless warming up. That’s why we don’t see a direct step-change like we did from epoch 2 to three within the very first loss curve we confirmed – these batches have been solely seen when the LR was low, so it couldn’t study a lot.
In the direction of the top of that first 10% of the epoch, the coaching loss plummets, as a result of the LR was excessive when these batches have been seen in the course of the first epoch, and the mannequin has discovered what they seem like. The mannequin shortly learns that it could actually very confidentally guess the proper reply.
However throughout this time, validation loss suffers. That’s as a result of though the mannequin is getting very assured, it’s not really getting any higher at making predictions. It has merely memorised the dataset, however isn’t bettering at generalizing. Over-confident predictions trigger validation loss to worsen, as a result of the loss perform penalizes extra assured errors larger.
The top of the curve is the place issues get notably attention-grabbing. The coaching loss begins getting worse – and that basically by no means should occur! In reality, neither of us bear in mind ever seeing such a factor earlier than when utilizing an inexpensive LR.
However really, this makes good sense underneath the memorization speculation: these are the batches that the mannequin noticed at a time when the LR had come again down once more, so it wasn’t capable of memorize them as successfully. However the mannequin remains to be over-confident, as a result of it has simply acquired a complete bunch of batches practically completely appropriate, and hasn’t but adjusted to the truth that it’s now seeing batches that it didn’t have an opportunity to study so properly.
It steadily recalibrates to a extra affordable stage of confidence, however it takes some time, as a result of the LR is getting decrease and decrease. Because it recalibrates, the validation loss comes again down once more.
For our subsequent experiment, we tried 1cycle coaching over 3 epochs, as a substitute of CLR – that’s, we did a single LR warmup for 10% of batches at first of coaching, after which decayed the LR over the remaining batches following a cosine schedule. Beforehand, we did a separate warmup and decay cycle for every epoch. Additionally, we elevated the LoRA rank, leading to slower studying. Right here’s the ensuing loss curve:
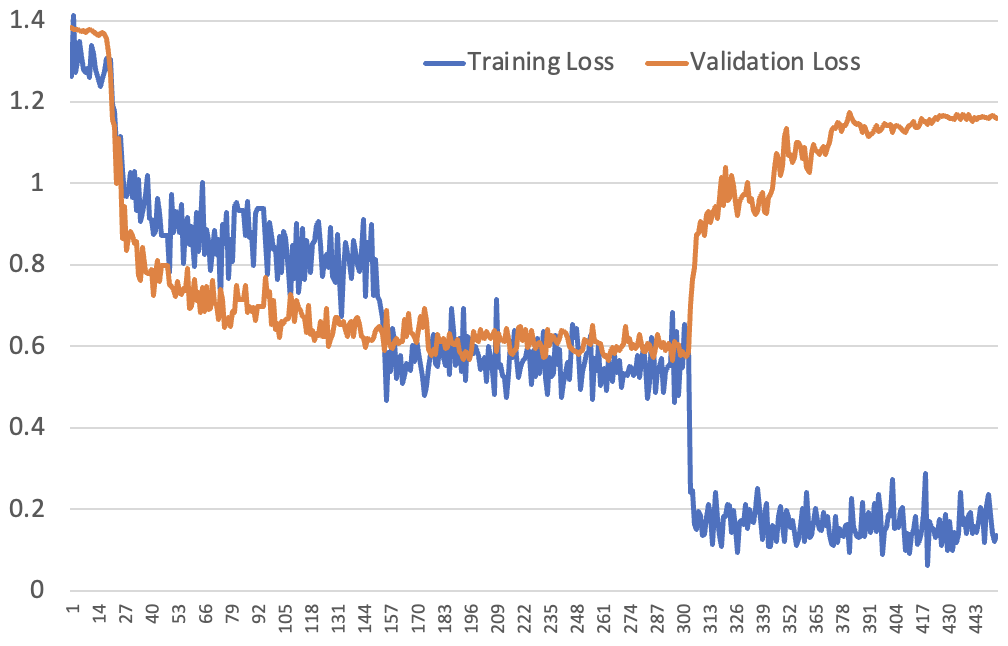
The form largely follows what we’d count on, primarily based on the earlier dialogue, aside from one factor: the validation loss doesn’t leap up at epoch 2 – it’s not till epoch 3 that we see that leap. Nevertheless beforehand the coaching loss was round 0.2 by the 2nd epoch, which is just attainable when it’s making extremely assured predictions. Within the 1cycle instance it doesn’t make such assured predictions till the third epoch, and we don’t see the leap in validation loss till that occurs.
It’s vital to notice that the validation loss getting worse doesn’t imply that we’re over-fitting in follow. What we usually care about is accuracy, and it’s advantageous if the mannequin is over-confident. Within the Kaggle competitors the metric used for the leaderboard is Imply Common Precision @ 3 (MAP@3), which is the accuracy of the ranked top-3 multiple-choice predictions made my the mannequin. Right here’s the validation accuracy per batch of the 1cycle coaching run proven within the earlier chart – as you see, it retains bettering, even though the validation loss acquired worse within the final epoch:
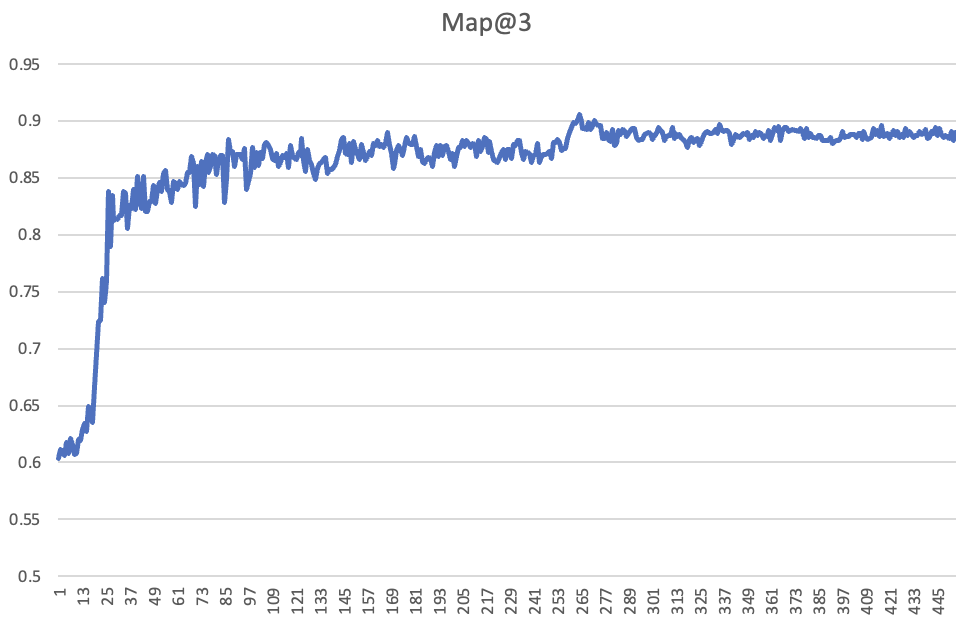
For those who’re excited about diving deeper, check out this report the place Johno shares logs from some extra examples, together with a pocket book for individuals who’d prefer to see this impact in motion for themselves.
How may the memorization speculation be true?
There isn’t a elementary legislation that claims that neural networks can’t study to recognise inputs from a single instance. It’s simply what researchers and practitioners have usually discovered to be the case in follow. It takes loads of examples as a result of the loss surfaces that we’re making an attempt to navigate utilizing stochastic gradient descent (SGD) are too bumpy to have the ability to leap far without delay. We do know, nevertheless, that some issues could make loss surfaces smoother, corresponding to utilizing residual connections, as proven within the basic Visualizing the Loss Panorama of Neural Nets paper (Li et al, 2018).
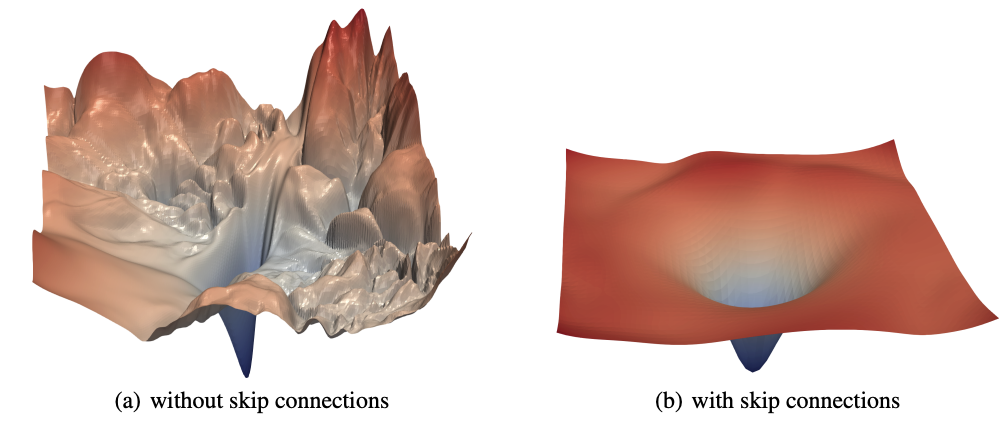
It may properly be the case that pre-trained giant language fashions have extraordinarily clean loss surfaces in areas near the minimal loss, and that loads of the fine-tuning work achieved within the open supply group is on this space. That is primarily based on the underlying premise surrounding the unique improvement of fine-tuned common language fashions. These fashions have been first documented within the ULMFiT paper again in 2018 by one in all us (Jeremy) and Sebastian Ruder. The rationale Jeremy initially constructed the ULMFiT algorithm is as a result of it appeared crucial that any mannequin that would do a very good job of language modeling (that’s, predicting the subsequent phrase of a sentence) must construct a wealthy hierarchy of abstractions and capabilities internally. Moreover, Jeremy believed that this hierarchy may then be simply tailored to resolve different duties requiring comparable capabilities utilizing a small quantity of fine-tuning. The ULMFiT paper demonstrated for the primary time that that is certainly precisely what occurs.
Giant language fashions, which at this time are orders of magnitude larger than these studied in ULMFiT, will need to have a fair richer hierarchy of abstractions. So fine-tuning one in all these fashions to, as an example, reply multiple-choice questions on science, can largely harness capabilities and information that’s already out there within the mannequin. It’s only a case of surfacing the best items in the best manner. These shouldn’t require many weights to be adjusted very a lot.
Based mostly on this, it’s maybe not stunning to assume {that a} pre-trained language mannequin with a small random classification head might be in part of the burden area the place the loss floor easily and clearly factors precisely within the route of a very good weight configuration. And when utilizing the Adam optimiser (as we did), having a constant and clean gradient ends in efficient dynamic studying price going up and up, such that steps can get very large.
What now?
Having a mannequin that learns actually quick sounds nice – however really it signifies that loads of fundamental concepts round how one can prepare fashions could also be turned on their head! When fashions prepare very slowly, we are able to prepare them for a very long time, utilizing all kinds of knowledge, for a number of epochs, and we are able to count on that our mannequin will steadily pull out generalisable data from the information we give it.
However when fashions study this quick, the catastrophic forgetting downside could out of the blue develop into much more pronounced. As an illustration, if a mannequin sees ten examples of a quite common relationship, after which one instance of a much less widespread counter-example, it might properly bear in mind the counter-example as a substitute of simply barely downweighting its reminiscence of the unique ten examples.
It could even be the case now that knowledge augmentation is now much less helpful for avoiding over-fitting. Since LLMs are so efficient at pulling out representations of the data they’re given, mixing issues up by paraphrasing and back-translation could not make a lot of a distinction. The mannequin can be successfully getting the identical data both manner.
Maybe we are able to mitigate these challenges by vastly rising our use of strategies corresponding to dropout (which is already used just a little in fine-tuning strategies corresponding to LoRA) or stochastic depth (which doesn’t appear to have been utilized in NLP to any important extent but).
Alternatively, possibly we simply have to be cautious to make use of wealthy mixtures of datasets all through coaching, in order that our fashions by no means have an opportunity to neglect. Though Llama Code, as an example, did endure from catastrophic forgetting (because it acquired higher at code, it acquired a lot worse at all the pieces else), it was fine-tuned with solely 10% of non-code knowledge. Maybe with one thing nearer to a 50/50 combine it might have been attainable to get simply nearly as good at coding, with out shedding its present capabilities.
For those who give you any different hypotheses, and are capable of check them, or in the event you discover any empirical proof that the memorization speculation is flawed, please do tell us! We’re additionally eager to listen to about different work on this area (and apologies if we did not reference any prior work right here), and any concepts about how (if in any respect) we must always alter how we prepare and use these fashions primarily based on these observations. We’ll be keeping track of replies to this twitter thread, so please reply there when you’ve got any ideas or questions.
[ad_2]