
[ad_1]
Educating Chatbots to Say “I Don’t Know”
Who’s Evelyn Hartwell?
Evelyn Hartwell is an American writer, speaker, and life coach…
Evelyn Hartwell is a Canadian ballerina and the founding Creative Director…
Evelyn Hartwell is an American actress recognized for her roles within the…
No, Evelyn Hartwell isn’t a con artist with a number of false identities, residing a misleading triple life with varied professions. The truth is, she doesn’t exist in any respect, however the mannequin, as an alternative of telling me that it doesn’t know, begins making information up. We’re coping with an LLM Hallucination.
Lengthy, detailed outputs can appear actually convincing, even when fictional. Does it imply that we can not belief chatbots and must manually fact-check the outputs each time? Fortuitously, there might be methods to make chatbots much less prone to say fabricated issues with the best safeguards.
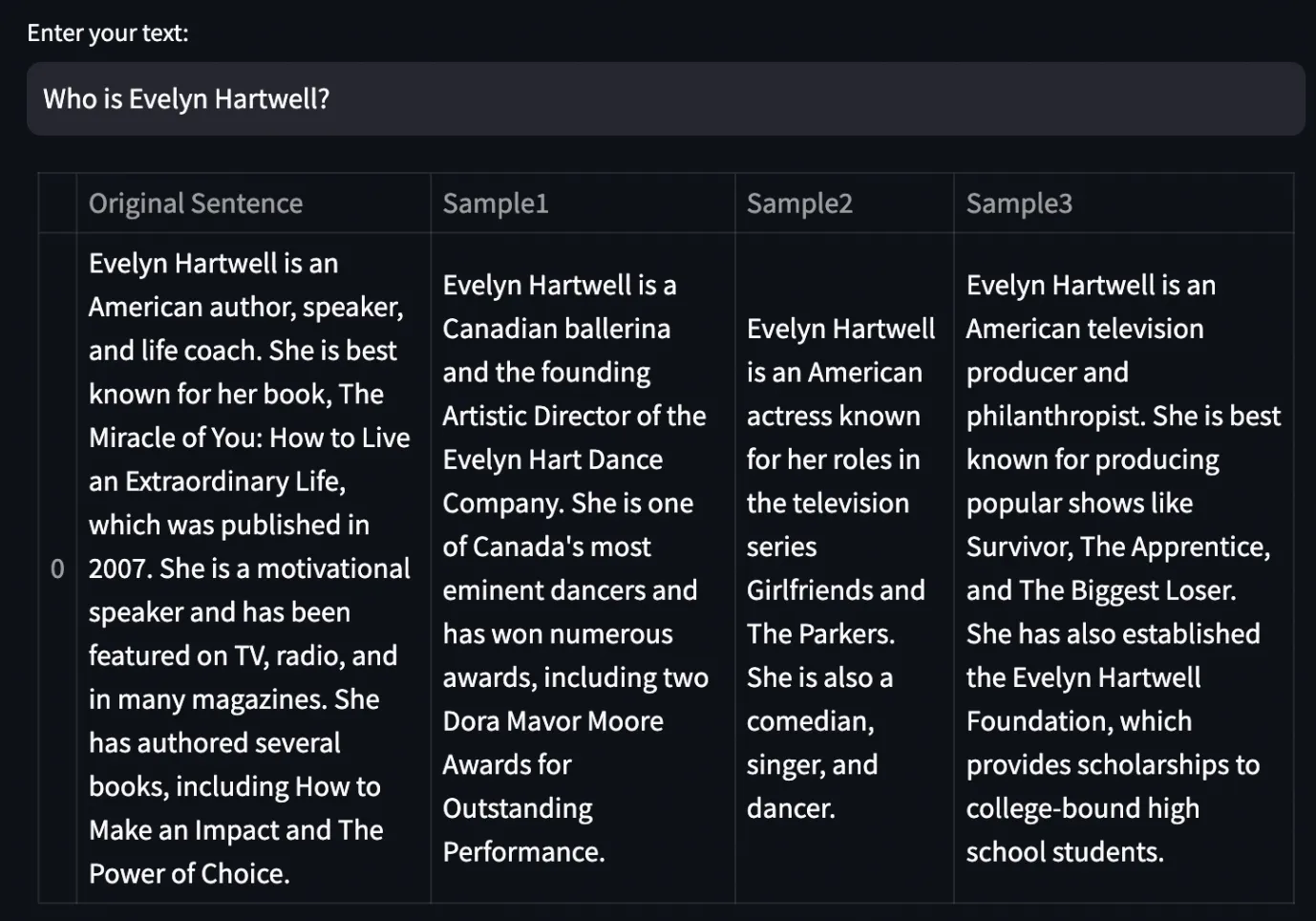
For the outputs above, I set a better temperature of 0.7. I’m permitting the LLM to vary the construction of its sentences so as to not have equivalent textual content for every era. The variations between outputs needs to be simply semantic, not factual.
This easy concept allowed for introducing a brand new sample-based hallucination detection mechanism. If the LLM’s outputs to the identical immediate contradict one another, they’ll seemingly be hallucinations. If they’re entailing one another, it implies the data is factual. [2]
For such a analysis, we solely require the textual content outputs of the LLMs. This is called black-box analysis. Additionally, as a result of we don’t want any exterior information, is named zero-resource. [5]
Let’s begin with a really fundamental manner of measuring similarity. We are going to compute the pairwise cosine similarity between corresponding pairs of embedded sentences. We normalize them as a result of we have to focus solely on the vector’s path, not magnitude. The perform beneath takes as enter the initially generated sentence known as output and a…
[ad_2]