
[ad_1]
Find out how to enhance accuracy, velocity, and token utilization of AI brokers

Introduction
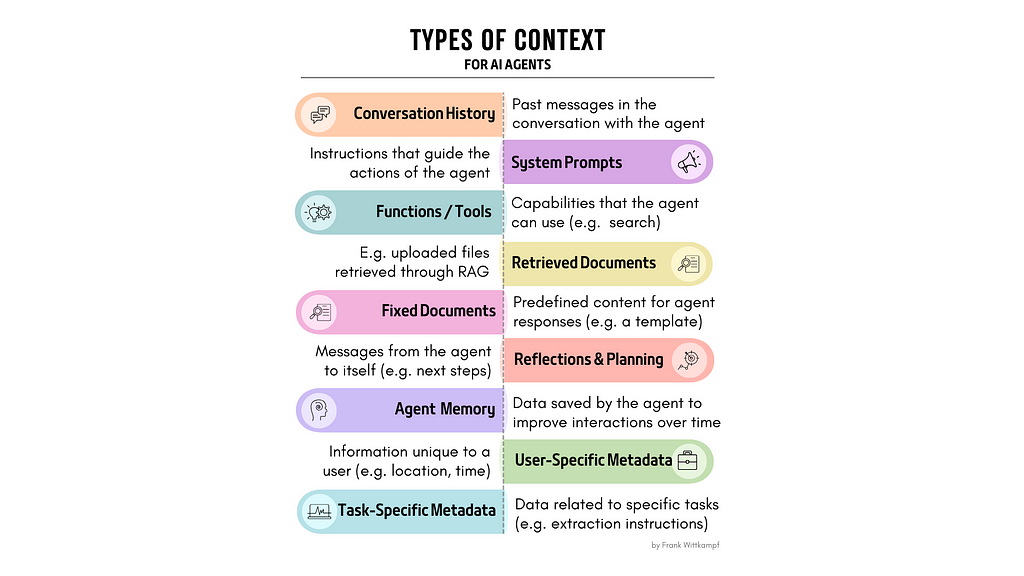
The conduct of an AI agent is outlined by two issues: (1) the mannequin it runs on and (2) the context that you just present to the mannequin. How you present this context determines the standard of the output of the agent. You possibly can even say that the conduct that distinguishes two AI brokers working on the identical mannequin is totally outlined by their context. So, what can we imply with context for an agent? See the Varieties of Context (picture) under for examples.
This text delves into extra superior strategies to boost AI agent effectivity and accuracy by selectively tailoring context in keeping with the wants of an agent. First I’ll describe 5 ways, after which some further implementation suggestions. The learnings within the article come from in depth expertise in working with multi-agent groups in a manufacturing surroundings, however are simply as relevant to single agent methods.
Understanding Contextual Wants
Most on-line examples and tutorials simplify their strategy to context (e.g. making use of a hard and fast cutoff size). Actual AI functions want a extra subtle strategy.
Totally different brokers have totally different contextual wants relying on the duty at hand. Some brokers might solely require simply the prior message, whereas different brokers would possibly want in depth historic information to reply precisely. These variations counsel {that a} tailor-made strategy to context administration for every agent is wanted.
Contemplate the next instance of an ongoing dialog between a consumer and a couple of brokers (a SW developer and a SW reviewer):
1 Person: “Please enhance the sorting operate I wrote from the uploaded file”
2 System_prompt_for_coder: “You're a SW developer, you assist the consumer to
develop …”
3 Coding_agent: “read_file_function”
4 Function_response: “coding snippet: ```some returned code```”
5 System_prompt_for_coder: “You're a SW developer, you assist the consumer to
develop …”
6 Coding_agent: “I’ve improved your code by including … and … to your code,
right here is the brand new operate …”
7 System_prompt_for_reviewer: “you're a SW code reviewer, you …”
8 Code_reviewer_agent: “After reviewing the improved code, there
are a couple of extra issues that I'd add to the code …"
9 System_prompt_for_coder: “you're a SW developer, you assist the consumer to
develop …”
10 Coding_agent: “ … ”
The context, as outlined on this instance is clearly repetitive and inefficient. Many strains are repeated (e.g. the system prompts), and every agent is getting extra context than it wants. Let’s assessment a couple of methods to enhance the context dealing with.
Tactic 1: Message Labeling
Message labeling is a vital device for managing and optimizing the interplay between AI brokers and their duties. By assigning metadata to every message within the dialog, we will neatly choose the data that’s most related to the agent’s job at hand. This tactic includes a number of key methods:
Relevance Labeling: Every message must be tagged with labels that replicate its relevance to ongoing and future interactions. This course of includes analyzing the content material of the message and figuring out its potential utility for the agent’s decision-making processes. For instance, messages that comprise questions, choices or insights must be marked as extremely related.
Permanence Labeling: It is important to categorize messages based mostly on their longevity and usefulness over time. Some messages, akin to these containing foundational choices or milestone communications, maintain long-term worth and must be retained throughout classes. In distinction, system messages would possibly solely be wanted as soon as in a selected second. These must be excluded from the agent’s reminiscence as soon as their rapid relevance has handed.
Supply and Affiliation Labeling: This includes figuring out the origin of every message, whether or not or not it’s from a selected agent, a consumer, operate, or different course of. This labeling helps in setting up a structured and simply navigable historical past that enables brokers to effectively retrieve and reference data based mostly on supply or job relevance.
Making use of good labels to the metadata of a message means that you can use good choice. Maintain studying for some examples.
Tactic 2: Agent-specific context necessities
Totally different brokers have totally different necessities. Some brokers can function on little or no data, whereas others want plenty of context to function appropriately. This tactic builds on the labeling we simply mentioned.
Vital Context Identification: It’s essential to determine which messages are vital for every particular agent and concentrate on these to streamline processing and improve response accuracy. Let’s have a look at line 8 within the context above. The code reviewer solely wants a restricted quantity of context to have the ability to precisely do its work. We will even say with some certainty that it’s going to produce a worse reply if we give it greater than the required context.
So what context does it want? Take a fast look, and also you’ll infer that the code reviewer solely wants its personal system immediate, and it wants the final agent message earlier than it, containing the newest iteration of the code (line 6).
Due to this fact, every agent must be configured such that it selects solely the historical past that it wants. The code reviewer solely appears on the final 2 messages, whereas the code author wants an extended historical past.
Tactic 3: Optimization of System Prompts
Placement: While you do a fast search on brokers and system prompts, it’s clear that placement of a system immediate for an agent issues. Ought to or not it’s the primary message within the chain, the final message? Opinions and outcomes range, relying on the use case. For instance, which provides a greater end result?
1) consumer: "I visited dr. Fauci on Thursday, and received recognized with …"
2) system: "Extract all medically related information from the consumer immediate"
Or
1) system: "Extract all medically related information from the consumer immediate"
2) consumer: "I visited dr. Fauci on Thursday, and received recognized with …"
In the event you take a look at this with a bigger and extra advanced historical past, you’ll discover that totally different placement of the identical instruction produces totally different outcomes. What is evident is that system prompts must be deliberately positioned in a selected place, and that this depends upon the agent and use case.
Be aware: in my expertise it depends upon the LLM to know if the system immediate must be the final message within the chain. Usually placing it because the final message is an effective selection (with particular exceptions, e.g. data extraction).
Permanence: Secondly, along with placement of system prompts, in most use circumstances you must be certain that a system immediate is labeled as “fleeting”. What I imply with a fleeting message, is that it doesn’t stay within the chat historical past after it has been used.
For instance, agent1 would possibly get a immediate that it ought to step again and replicate on the issue. One flip later, agent1 is requested to make use of its reflection to discover a answer to the issue. In that second flip, the preliminary immediate (to replicate) will solely confuse the agent and end in a worse reply. It will have been higher if that preliminary system immediate was not everlasting, and wouldn’t have been supplied to the agent once more. Within the instance under, which means line #2 must be eliminated while you make your second LLM name to the agent.
#1 Person:
"What's the which means of the universe?"
#2 System:
"You're a thinker; earlier than you reply, step again and
replicate on what the consumer's query implies."
#3 Agent_philo:
"Reflecting on this query, one can take into account the universe
by varied philosophical lenses - existentialism views
it as a canvas for creating private which means, whereas cosmology
sees it as a playground for understanding bodily legal guidelines. This
interaction between human notion and scientific exploration
is central to understanding our question."
#4 System:
"You're a thinker, and also you simply mirrored deeply on the
query posed by the consumer. Use that insightful reflection to
craft a complete reply."
#5 Agent_philo:
"From an existentialist perspective, the which means of the universe
is a private journey, the place every particular person constructs their very own
which means by decisions and life experiences. In distinction, from a
cosmological viewpoint, it's about exploring and understanding
the huge, intricate legal guidelines that govern the cosmos. These views
assist us grasp the multifaceted nature of our universe, mixing our
existential quests with scientific inquiry."
This strategy ensures that any previous system immediate is faraway from the chain, and that every immediate is positioned optimally. Now now we have an uncluttered dialog historical past, permitting for extra exact and predictable interactions.
Tactic 4: Lowering redundancy in your RAG
We may dedicate a dozen articles to optimizing your agent by bettering the way you do RAG, however will maintain it contained to some paragraphs right here. The sheer quantity of tokens that may come from utilizing RAG is so massive that now we have to say a couple of methods on find out how to handle it. In the event you haven’t already, this can be a matter you must spend appreciable time researching.
Fundamental tutorials on RAG principally assume that the paperwork that you just or your consumer uploads are easy and simple. Nevertheless, in follow most paperwork are advanced and unpredictable. My expertise is that plenty of paperwork have repetitive data. For instance, the identical data is commonly repeated within the intro, physique, and conclusion of a PDF article. Or a medical file could have repetitive physician updates with (nearly) the identical data. Or logs are repeated time and again. Additionally, particularly in manufacturing environments, when coping with retrieval throughout a big physique of recordsdata, the content material returned by a normal RAG course of might be extraordinarily repetitive.
Coping with Duplicates: A primary step to optimize your RAG context, is to determine and take away precise and close to duplicates inside the retrieved doc snippets to stop redundancy. Precise duplicates are simple to determine. Close to duplicates might be detected by semantic similarity, by taking a look at variety of vector embeddings (numerous snippets have vectors which have a bigger distance from one another), and plenty of different methods. The way you do that might be extraordinarily dependent in your use case. Listed below are a few examples (by perplexity)
Variety in Responses: One other means to make sure variety of RAG responses by neatly grouping content material from varied recordsdata. A quite simple, however efficient strategy is to not simply take the highest N paperwork by similarity, however to make use of a GROUP BY in your retrieval question. Once more, should you make use of this relies extremely in your use case. Right here’s an instance (by perplexity)
Dynamic Retrieval: So, provided that this text is about dynamic context, how do you introduce that philosophy into your RAG course of? Most RAG processes retrieve the highest N outcomes, e.g. the highest 10 most related doc snippets. Nevertheless, this isn’t how a human would retrieve outcomes. While you seek for data, you go to one thing like google, and also you search till you discover the fitting reply. This might be within the 1st or 2nd search end result, or this might be within the twentieth. After all, relying in your luck and stamina ;-). You possibly can mannequin your RAG the identical means. We will permit the agent to do a extra selective retrieval, solely giving it the highest few outcomes, and have the agent resolve if it desires extra data.
Right here’s a steered strategy. Don’t simply outline one similarity cutoff, outline a excessive, medium and low cutoff level. For instance, the outcomes of your search might be 11 very related, 5 medium, and 20 considerably related docs. If we are saying the agent will get 5 docs at a time, now you let the agent itself resolve if it desires extra or not. You inform the agent that it has seen 5 of the 11 very related docs, and that there are 25 extra past that. With some immediate engineering, your agent will rapidly begin appearing far more rationally when searching for information.
Tactic 5: Superior Methods for Context Processing
I’ll contact upon a couple of methods to take dynamic context even a step additional.
On the spot Metadata: As described in tactic 1, including metadata to messages will help you to preselect the historical past {that a} particular agent wants. For many conditions, a easy one phrase textual content label must be adequate. Understanding that one thing comes from a given operate, or a selected agent, or consumer means that you can add a easy label to the message, however should you take care of very massive AI responses and have a necessity for extra optimization, then there’s a extra superior means so as to add metadata to your messages: with AI.
Just a few examples of this are:
- A easy option to label a historical past message, is to make a separate AI name (to a less expensive mannequin), which generates a label for the message. Nevertheless, now you’re making 2 AI calls every time, and also you’re introducing further complexity in your move.
A extra elegant option to generate a label is to have the unique creator of a message generate a label similtaneously it writes its response.
- Have the agent offer you a response in JSON, the place one aspect is its regular response, and the opposite aspect is a label of the content material.
- Use multi-function calling, and supply the agent a operate that it’s required to name, which defines the message label.
- In any operate name that the agent makes, reserve a required parameter which comprises a label.
On this means, you immediately generate a label for the operate contents.
One other superior technique to optimize context dynamically is to pre-process your RAG..
Twin processing for RAG: To optimize your RAG move, you would possibly think about using a less expensive (and sooner) LLM to condense your RAG outcomes earlier than they’re supplied into your normal LLM. The trick when utilizing this strategy, is to make use of a quite simple and non-disruptive immediate that condenses or simplifies the unique RAG outcomes right into a extra digestible kind.
For instance, you would possibly use a less expensive mannequin to strip out particular data, to scale back duplication, or to solely choose elements of the doc which can be related to the duty at hand. This does require that you realize what the strengths and weaknesses of the cheaper mannequin are. This strategy can prevent plenty of price (and velocity) when utilized in mixture with a extra highly effective mannequin.
Implementation
OK, so does all of the above imply that every of my brokers wants pages and pages of customized code to optimize its efficiency? How do I generalize these ideas and lengthen them?
Agent Structure: The reply to those questions is that there are clear methods to set this up. It simply requires some foresight and planning. Constructing a platform that may correctly run a wide range of brokers requires that you’ve an Agent Structure. In the event you begin with a set of clear design ideas, then it’s not very sophisticated to utilize dynamic context and have your brokers be sooner, cheaper, and higher. All on the identical time.
Dynamic Context Configuration is likely one of the components of your Agent Structure.
Dynamic Context Configuration: As mentioned on this article, every agent has distinctive context wants. And managing these wants can come right down to managing plenty of variation throughout all doable agent contexts (see the picture on the prime of the article). Nevertheless, the excellent news is that these variations can simply be encoded into a couple of easy dimensions. Let me offer you an instance that brings collectively many of the ideas on this article.
Let’s think about an agent who’s a SW developer who first plans their actions, after which executes that plan. The context configuration for this agent would possibly be:
- Retain the preliminary consumer query
- Retain the plan
- Neglect all historical past aside from the final code revision and the final message within the chain
- Use RAG (on uploaded code recordsdata) with out RAG condensation
- At all times set system immediate as final message
This configuration is saved within the context configuration of this agent. So now your definition of an AI agent is that it’s greater than a set of immediate directions. Your agent additionally a has a selected context configuration.
You’ll see that throughout brokers, these configurations might be very significant and totally different, and that they permit for a fantastic abstraction of code that in any other case can be very customized.
Rounding up
Correctly managing Dynamic context not solely enhances the efficiency of your AI brokers but in addition drastically improves accuracy, velocity, and token utilization… Your brokers at the moment are sooner, higher, and cheaper, all on the identical time.
Your agent shouldn’t solely be outlined by its immediate directions, it also needs to have its personal context configuration. Utilizing easy dimensions that encode a special configuration for every agent, will drastically improve what you possibly can obtain together with your brokers.
Dynamic Context is only one aspect of your Agent Structure. Invite me to debate if you wish to be taught extra. Hit me up within the feedback part with questions or different insights, and naturally, give me a couple of clicks on the claps or comply with me should you received one thing helpful from this article.
Completely satisfied coding!
Subsequent-Degree Brokers: Unlocking the Energy of Dynamic Context was initially revealed in In the direction of Knowledge Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.
[ad_2]